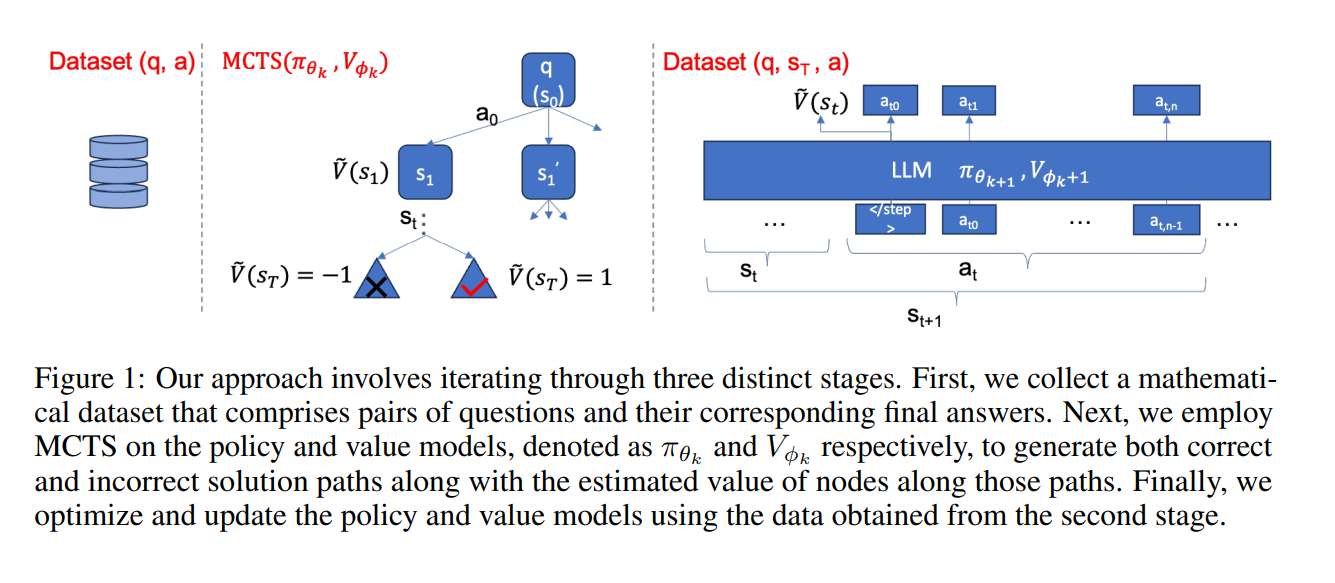
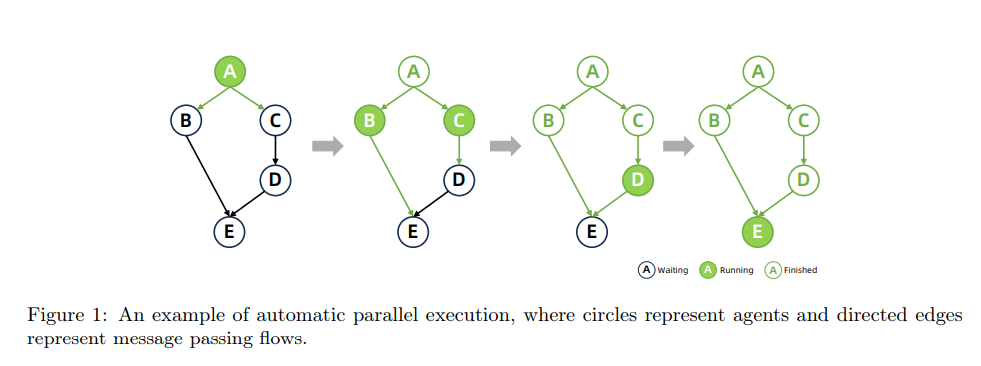
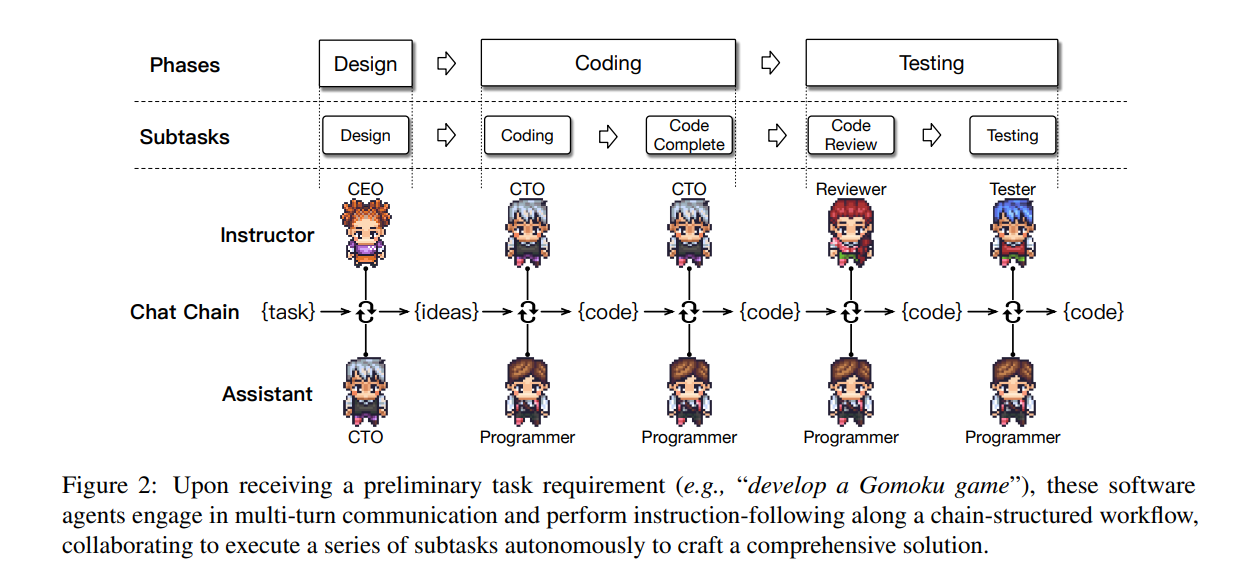
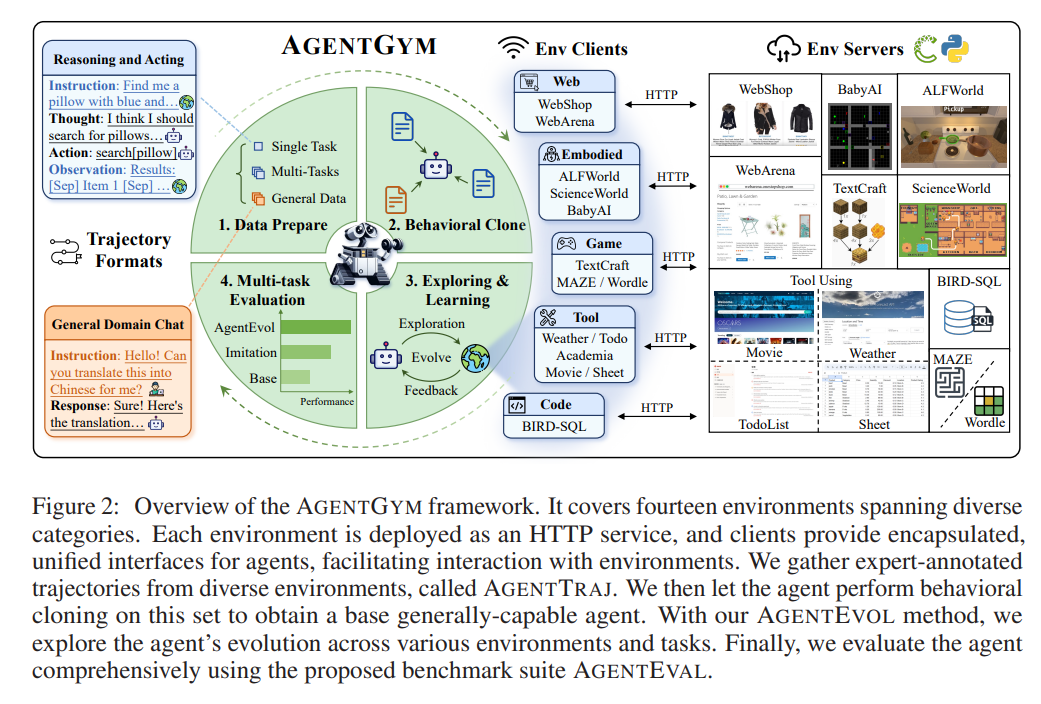
https://arxiv.org/abs/2401.01335 Self-Play Fine-Tuning Converts Weak Language Models to Strong Language ModelsHarnessing the power of human-annotated data through Supervised Fine-Tuning (SFT) is pivotal for advancing Large Language Models (LLMs). In this paper, we delve into the prospect of growing a strong LLM out of a weak one without the need for acquiring addiarxiv.orgpreliminary 알고리즘 간단하게