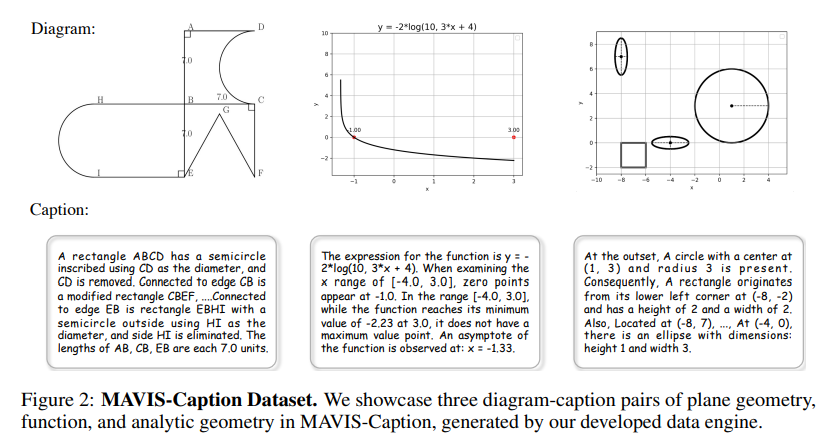
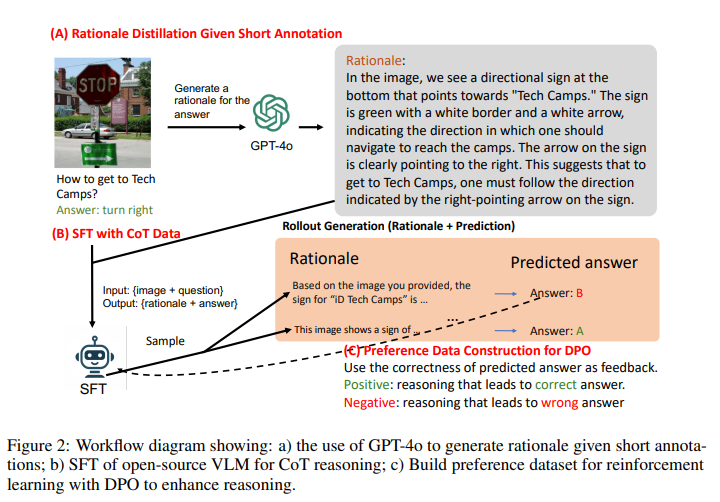
MAVIS: Mathematical Visual Instruction Tuning 논문리뷰
https://arxiv.org/pdf/2407.08739 Multi-modal Large Language Models (MLLMs) have recently emerged as a significant focus in academia and industry. Despite their proficiency in general multi-modal scenarios, the mathematical problem-solving capabilities in visual contexts remain insufficiently explored. We identify three key areas within MLLMs that need to be improved: visual encoding of math diag..