ReST 논문리뷰 Reinforced Self-Training (ReST) for Language Modeling https://arxiv.org/pdf/2308.08998요약 : Reward model + SFT 핵심 Grow stage에서 데이터셋을 샘플링 ~ current policy modelreward model을 통해 filtered improve 파트 NLL loss Figure 1 모식도 pseudo - 알고리즘 Reward 부여 방식 : 토큰 뒤에 scalar reward로 inference-time, RLHF/STaR, ReST 2024.10.09
ReST-MCTS 논문리뷰 self training에서는 intermediate 에러(wrong or useless)가 있는데도 우연히 결과가 올바른 false positive 데이터가 만들어지는 경우가 있다One way to tackle this issue 에는 verifier나 reward model이 있는데 (math-sheperd 논문, let's verify step by step 논문) 실제로 ReST , Self-Rewarding CoT , ToT, Self-Consistency , Best-of-N 를 outperform SC 다수의 reasoning trace 샘플후 frequent 선택BoNPRM 또는 ORM이 선택하는 것이 BoNHistorically, the main challenge with learni.. inference-time, RLHF/STaR, ReST 2024.08.28
Recursive intropspection 논문 리뷰 (Teaching LanguageModel Agents How to Self-Improve) https://arxiv.org/pdf/2407.18219v1RISE poses fine-tuning for a single-turn prompt as solving a multi-turn Markov decision process (MDP)SINGLE inference-time, RLHF/STaR, ReST 2024.07.28
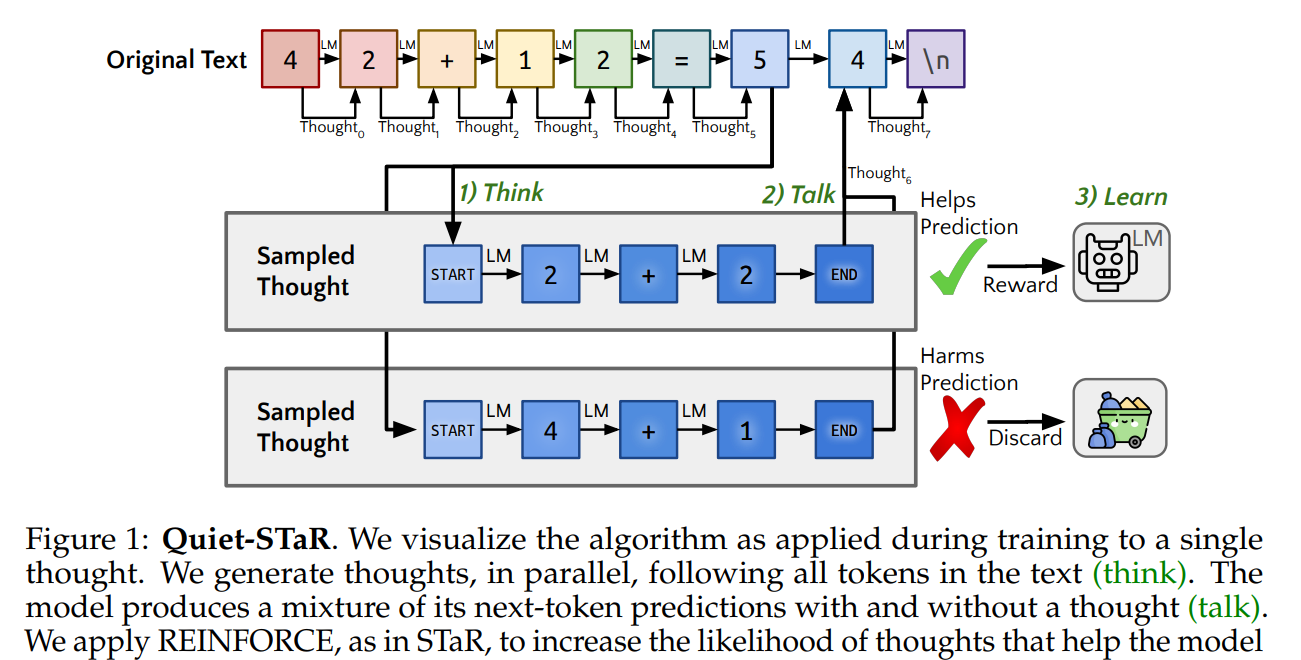
Quiet-STaR : AI 논문리뷰 기존의 연구들은 특정 reasoning 과제를 제공하거나 경우에 따라 reasoning 자체를 제공하기 위해 신중하게 선별된 데이터셋에 의존합니다.여기서 의문점이 만약 reasoning이 모든 텍스트에 내재되어 있다면, reasoning을 가르치기 위해 언어 모델링이라는 과제에 leverage 하지 말아야 할 이유가 있을까이다 1. Parallel rationale generation (think,2. Mixing post-rationale and base predictions (talk,3. Optimizing rationale generation (learn inference-time, RLHF/STaR, ReST 2024.07.17