self training에서는 intermediate 에러(wrong or useless)가 있는데도 우연히 결과가 올바른 false positive 데이터가 만들어지는 경우가 있다
One way to tackle this issue 에는 verifier나 reward model이 있는데 (math-sheperd 논문, let's verify step by step 논문)
실제로 ReST , Self-Rewarding CoT , ToT, Self-Consistency , Best-of-N 를 outperform
SC
다수의 reasoning trace 샘플후 frequent 선택
BoN
PRM 또는 ORM이 선택하는 것이 BoN
Historically, the main challenge with learning a PRM is the lack of supervised annotations per reasoning step
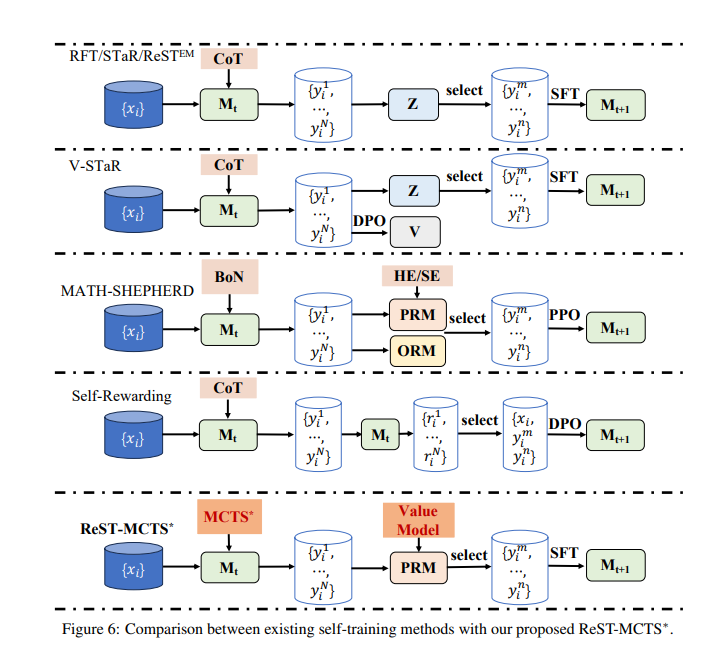
3. The ReST-MCTS∗ Method
4개의 main 구성요소
- MCTS∗: PRM의 지도를 받아 충분한 롤아웃 시간으로 트리 검색을 수행한다.
- PRM: 부분적인 솔루션의 품질을 평가하고 MCTS를 guide
- Policy Model: 각 질문에 대해 여러 중간 reasoning step를 생성한다.
- LLM Self-Training: MCTS∗를 사용하여 reasoning trace를 수집하고, 정책 모델을 positive 샘플로 훈련하며, 모든 생성된 traces를 통해 프로세스 보상 모델을 훈련한다.

중요한점 weighted reward
PRM + value function의 보상에 factor
정확히 현재 중간단계 reasoning step의 이전 스텝의 quality value와 현재 스텝의 weighted reward
k가 증가함에 따라 m는 감소하여 정답에 도달하는 데 필요한 추론 단계가 줄어듬
현재 단계의 가중 보상에 더 높은 가중치를 부여하게 된다
또한, w와 v가 아래의 정리에서 제시된 예상된 boundedness을 만족한다는 것을 derive


'inference-time, RLHF > STaR, ReST' 카테고리의 다른 글
| ReST 논문리뷰 Reinforced Self-Training (ReST) for Language Modeling (1) | 2024.10.09 |
|---|---|
| Recursive intropspection 논문 리뷰 (Teaching LanguageModel Agents How to Self-Improve) (0) | 2024.07.28 |
| Quiet-STaR : AI 논문리뷰 (0) | 2024.07.17 |