https://arxiv.org/pdf/2410.16198
https://github.com/RifleZhang/LLaVA-Reasoner-DPO
GitHub - RifleZhang/LLaVA-Reasoner-DPO
Contribute to RifleZhang/LLaVA-Reasoner-DPO development by creating an account on GitHub.
github.com
Chain-of-thought (CoT) reasoning in vision language models (VLMs) is crucial for improving interpretability and trustworthiness.
However, current training recipes lack robust CoT reasoning data, relying on datasets dominated by short annotations with minimal rationales.
In this work, we show that training VLM on short answers does not generalize well to reasoning tasks that require more detailed responses.
To address this, we propose a two-fold approach.
First, we distill rationales from GPT-4o model to enrich the training data and fine-tune VLMs, boosting their CoT performance.
Second, we apply reinforcement learning to further calibrate reasoning quality. Specifically, we construct positive (correct) and negative (incorrect) pairs of model-generated reasoning chains, by comparing their predictions with annotated short answers.
Using this pairwise data, we apply the Direct Preference Optimization algorithm to refine the model’s reasoning abilities.
Our experiments demonstrate significant improvements in CoT reasoning on benchmark datasets and better generalization to direct answer prediction as well.
This work emphasizes the importance of incorporating detailed rationales in training and leveraging reinforcement learning to strengthen the reasoning capabilities of VLMs.
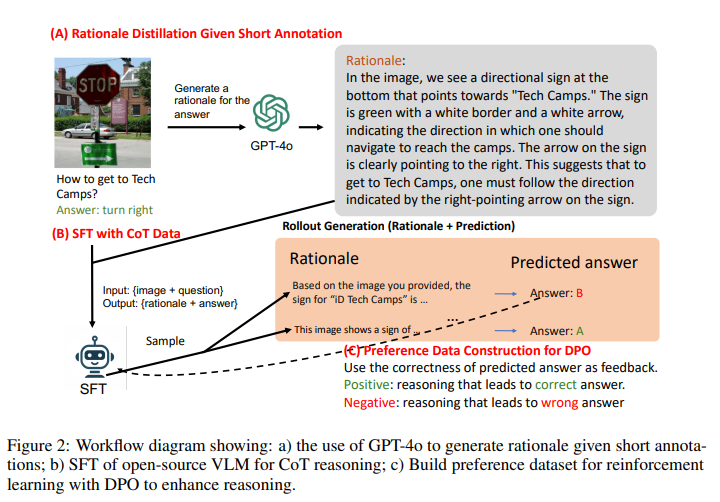
3 METHOD
As shown in fig. 2, our pipeline consists of three stages:
(A) CoT data distillation from GPT-4o (section 3.1), '
(B) SFT with CoT (and direct) data to enable VLM CoT reasoning, and
(C) RL for further enhancement of CoT reasoning.
The RL stage involves generating positive (correct) and negative (incorrect) reasoning data pairs sampled from SFT, as detailed in section 3.3.
3.1 REASONING DATA DISTILLATION
To mitigate the limited availability of high-quality CoT data, we leverage VQA datasets with short annotations and augment them with rationales generated by the GPT-4o model.
We collect 193k visual CoT instances to create the SHAREGPT-4O-REASONING dataset, which we plan to release for public use.
We focus on the following reasoning types as demonstrated in fig. 4:

Real-World Knowledge includes the A-OKVQA dataset (Schwenk et al., 2022), which covers a broad range of commonsense reasoning and real-world knowledge for answering questions.
Chart Understanding includes the ChartQA dataset (Zhang et al., 2024a), which involves tasks like item comparison, counting, and numerical computation.
Document Understanding/Real-World Text includes DocVQA (Mathew et al., 2021), InfoVQA (Mathew et al., 2022), and TextVQA (Singh et al., 2019), focusing on information localization and extraction in industrial documents and real-world image comprehension.
Math and Science includes MathVision (Wang et al., 2024), G-LLaVA (Gao et al., 2023), SQA (Lu et al., 2022), and AI2D (Kembhavi et al., 2016), focusing on scientific knowledge and mathematical reasoning.
After distillation, we filtered out examples whose answer predicted by GPT-4o is different from ground truth.
The data statistics are presented in table 1, and a comparison of answer lengths is shown in fig. 3, highlighting that CoT responses peak around 100 tokens, while direct answers are typically under 5 tokens.
The exact distillation prompt is provided in appendix A. 3.2 SUPERVISED FINE-TUNING FOR CHAIN-OF-THOUGHT PREDICTION
We choose LLaMA3-LLaVA-NeXT-8B as our base architecture, whose weight is initialized with the Open-LLaVA-NeXT weights1 .
To ensure the model handles both direct and chain-of-thought (CoT) predictions, we implement two types of prompts during training.
Direct Prediction: For direct prediction tasks, we use the prompt “Answer the question with a short answer” for short-answer questions, and “Answer with the option’s letter from the given choices directly” for multiple-choice questions.
CoT Prediction: For CoT prediction tasks, we use the prompt “Generate a reason first and then output a letter answer” for multiple-choice questions, and “Generate a reason first and then output a short answer” for short-answer questions.
In the model’s response, the rationale is followed by the answer, which is formatted as “### Answer: ” to enable answer extraction during evaluation.
3.3 REINFORCEMENT LEARNING FOR ENHANCED REASONING
To further improve the quality of reasoning chains, we apply RL using the DPO algorithm to better align the model’s reasoning process toward more accurate predictions.
The DPO algorithm requires both positive and negative responses.
To generate these, we use the SFT model as the policy model (i.e., generator), producing 32 candidate predictions per question (temperature 1.0 for short answer and 1.2 for multiple-choice questions).
Each prediction is compared with the ground truth to determine its correctness (fig. 2).
Following the approach in Dubey et al. (2024), we select instances with an accuracy between 0.25 and 0.85.
From these, we randomly pair positive and negative responses, creating up to three pairs per question.

4 SFT EXPERIMENTS FOR CHAIN-OF-THOUGHT LEARNING
In this section, we explore how SFT can enhance VLM reasoning by addressing two key research questions:
(1) Can CoT reasoning be implicitly learned from short responses? and
(2) How effectively can CoT be learned from GPT4o distilled data?
Additionally, we analyze the composition of CoT data across various reasoning capabilities and compare the performance of SOTA models with GPT-4o.
4.1 TRAINING SETTING As shown in the upper part of fig. 5, we present the data composition for SFT.
The training data includes CoT distillation (193k instances) from table 1 and corresponding short answers (193k).
Additionally, for CoT data, we incorporate 16k visual math examples from G-LLaVA.
To maintain general instruction-following capability as the base model, we include 2k randomly sampled instruction data from LLaVA pretraining Liu et al. (2024).
To ensure the SFT models can handle both direct and CoT prompts during inference, we sample a small set of format-aligned data—50 examples from each of the 9 datasets—resulting in 450 instances.
In the lower part of fig. 5, we outline the data composition for model training.
Specifically, LLAVANEXT-FORMAT (fig. 5 ①) serves as the baseline model, trained exclusively on format-aligned data to enforce the desired output format without learning any task-specific reasoning skills.
In contrast, models in fig. 5 ② and ③ incorporate either direct or CoT datasets, enabling the model to be expert in one type of skill as well as following the both direct and CoT prompt styles.
Finally, LLAVAREASONER-SFT (fig. 5 ④) represents the SFT model trained on both CoT and direct data, making it to be expert in both types of reasoning.
We use the LLaMA3-LLaVA-NeXT-8B architecture, initializing the weights with Open-LLaVANeXT.
All Supervised Fine-Tuning (SFT) experiments are trained for 1 epoch with a learning rate of 5e-6 and a batch size of 32.
The experiments are conducted on 8 H100 GPUs.
4.2 EVALUATION SETTING
We evaluate our method using a range of benchmark datasets, including A-OKVQA (Schwenk et al., 2022), ChartQA (Masry et al., 2022), DocVQA (Mathew et al., 2021), InfoVQA Mathew et al. (2022), TextVQA (Mathew et al., 2021), AI2D (Kembhavi et al., 2016), ScienceQA (Lu et al., 2022), and MathVista (Lu et al., 2023).
We also conduct more evaluation on general datasets OCRBench (Liu et al., 2023c), MMStar (Chen et al., 2024a), and MMMU (Yue et al., 2024) in later sections.
The evaluation for A-OKVQA was implemented by us, while for the other datasets, we follow the evaluation protocols outlined in VLMEval (Duan et al., 2024).
For CoT evaluation, answers are extracted after the pattern "###Answer: " before sent to evaluation.
More comparison with LLaMA3-LLaVA-NeXT-8B model is shown appendix C and evaluation on GPT-4o is shown in appendix B.
4.3 CAN REASONING BE IMPLICITLY LEARNT FROM DIRECT PREDICTION?
Table 2 presents the performance of the models introduced in fig. 5. Since LLAVA-NEXT-8B training data contains very few CoT reasoning examples, CoT performance of ① lags behind direct prediction across most tasks.
The only improvement is observed in ChartQA and MathVista with a modest gain of +1.0 in CoT performance, showing CoT is helpful for calculation related tasks.
When comparing model trained on direct only data (②) to that trained on format-aligned data (①), we observe an average gain of +5.6 in direct prediction accuracy (65.5 → 71.1) and a +2.9 improvement in CoT performance (62.7 → 65.6).
Surprisingly, closer inspection of CoT performance in calculationinvolved tasks, such as ChartQA and MathVista, reveals only marginal gains (+0.6 for ChartQA CoT) or even a performance drop (-1.7 on MathVista), which contrasts with the improvements seen on the two tasks in ①.
On text-rich tasks, positive gains (>1) are observed, with the most improvement seen in InfoVQA (+3.7).
Significant gains are also evident in science-related tasks like AI2D (+5.1) and SQA (+11.0).
Despite these improvements, CoT performance still trails behind direct prediction overall (CoT: 65.6 vs. direct: 71.1).
This result suggests that training on direct only prediction may not effectively help with CoT prediction When comparing the model trained on CoT-only data (③) with the one trained on format-aligned data (①), we observe improvements in both direct and CoT predictions.
Direct prediction performance increases by an average of +4.2 (65.5 → 69.7), while CoT prediction improves significantly by +10.5 (62.7 → 73.2).
Notably, the CoT performance of the model ③ surpasses its direct prediction (73.2 CoT vs. 69.7 direct).
Significant gains are observed in calculation-intensive tasks like ChartQA and MathVista, with increases of +11.0 and +8.9 in CoT performance, respectively.
Interestingly, for text-rich tasks such as DocVQA, InfoVQA, and TextVQA, the direct performance of model ③ (trained on CoT-only data) outperforms that of model ② (trained on direct-only data).
This suggests that even for text-heavy tasks, reasoning processes, such as localizing information in documents or recognizing text in real-world scenarios, may benefit from CoT training.
The skills learned from CoT training appear to generalize to direct prediction as well When both CoT and direct data are combined (④), performance is further enhanced for both prediction types, with an average gain of +7.3 in direct prediction (65.5 → 72.8) and +11.7 in CoT prediction (62.7 → 74.4).
This demonstrates that combining direct and CoT data yields the best overall performance.
Interestingly, in model ④, for 3 out of 8 datasets (TextVQA, DocVQA, AI2D), direct prediction outperforms CoT prediction.
We hypothesize that these tasks involve a significant proportion of concise fact extraction, where generating long-form CoT responses may not provide additional benefits or even hurts.
Further validation of this hypothesis will be explored in future work.
4.5 ABLATION TESTS ON DATA COMPOSITION
Data Composition for Math.
In table 3, we examine the effectiveness of data composition on MathVista performance.
We first include two visual math datasets: MathVision (MV) and G-LLaVA (GL). Including MV improves CoT performance by +3.1 over format only baseline (fig. 5 ①), while adding GL yields an additional gain of +1.5.
Building on MV+GL, we incorporate several datasets that are potentially relevant to the task, including two math text-only datasets: MathPlus (MP) and MathInstruct (MI), two science datasets: SQA and AI2D, and ChartQA.
Notably, ChartQA significantly boosts CoT performance (+5.5), while AI2D and SQA provide positive gains of +0.6 and +1.5, respectively.
However, adding the math text datasets results in minimal improvement.
Comparing inclusion of 100k MP vs 50k MP, more text data does not necessarily lead to better results. Therefore, we decided not to include them in training LLAVA-REASONER-SFT.
Data Composition for Science Tasks with CoT Prediction.
In table 4, we evaluate the impact of data composition on science datasets, including AI2D and SQA.
Our results show that combining SQA and AI2D provides additional gains on both datasets, indicating that they are mutually beneficial.
Furthermore, adding ChartQA contributes positively to both datasets, with a notable improvement of +0.7 for AI2D.
4.6 COMPARING WITH SOTA MODEL AND GPT-4O
In table 5, we compare the performance of GPT-4o and a recent state-of-the-art model, Cambrian Tong et al. (2024).
For GPT-4o, we include both direct and CoT predictions, following the prompt optimization steps outlined in Borchmann (2024), with the prompts detailed in appendix B.
For Cambrian, we report the numbers from Tong et al. (2024) and replicated the results using the official checkpoint on MMStar, InfoVQA, and A-OKVQA.
Specifically for Cambrian, CoT predictions were used for the MathVista dataset, while direct predictions were applied for the remaining datasets.
When compared to open-source models, GPT4o outperforms on nearly all benchmark datasets, with the exception of SQA.
Notably, significant improvements from CoT predictions are observed on tasks involving calculation or complex reasoning, such as ChartQA, MathVista, MMMU, and MMStar. Cambrian-7B is trained on a dataset of 7 million open-source instruction-following examples.
In contrast, our model, fine-tuned on fewer than 400k instruction examples, outperforms Cambrian-7B on most benchmark datasets, underscoring the effectiveness of incorporating CoT data.
While we recognize the challenge of comparing against other models, such as One-Vision (Li et al., 2024), MiniCPM-V Yao et al. (2024), X-Composer Zhang et al. (2024b), and InternVL Chen et al. (2024b), due to differences in model architecture, training datasets, and evaluation pipelines, our primary focus is on studying the effectiveness of CoT learning rather than competing for state-of-the-art performance on visual-language tasks.
5 RL EXPERIMENTS FOR ENHANCED CHAIN-OF-THOUGHT REASONING
In this section, we demonstrate the effectiveness of RL in further enhancing CoT reasoning.
We employ the DPO algorithm, which is directly optimized using positive and negative pairs.
By leveraging short-answer feedback (section 3.3), we construct preference pairs across three domains: A-OKVQA (real-world knowledge reasoning), ChartQA (chart interpretation), and math (MathVision and G-LLaVA).
Although additional DPO data from other datasets could be incorporated, data scaling and balancing will be addressed in future work.
For the DPO dataset, we include 24.5k examples from ChartQA, 18.3k from A-OKVQA, and 22.0k from math domain, totaling 64.8k preference data pairs.
We train LLAVA-REASONER-SFT on this dataset using a learning rate of 5e-7, a batch size of 32, and for 1 epoch.
We found an additional trick to truncate the responses up to 90 tokens to be helpful for DPO training.
To compare the effectiveness of different DPO datasets, we include RLAIF-V Yu et al. (2024), which contains 80k DPO pairs representing the state-of-the-art dataset for aligning VLMs for reducing hallucinations.
5.1 CAN DPO CALIBRATE REASONING?

In table 6, we present the results of the DPO model optimized on top of LLAVA-REASONER-SFT (④).
Model ⑤ uses the SOTA RLAIF-V Yu et al. (2024) data, while model ⑥ uses our dataset.
We observe that Model ⑤ shows a slight improvement in both direct prediction (+0.2) and CoT prediction (+0.2), whereas model ⑥ demonstrates a greater improvement in CoT prediction (+1.1) with equal gains on direct prediction.
Interestingly, though only 3 out of 8 datasets are selected to construct DPO pairs, gains are observed across 7 out of 8 datasets except for SQA with a slight decrease (92.9 → 92.6).
These results suggest that DPO dataset constructed from model-generated rationales can effectively enhance reasoning accuracy and show generalization across tasks.

5.2 DPO AS VERIFIER FOR COT REASONING RE-RANKING
In fig. 6, we present the re-ranking results using the DPO model as a verifier, following the approach of Zhang et al. (2024d); Hosseini et al. (2024); Lu et al. (2024). The DPO reward score is calculated as

When trained with RLAIF-V data (⑤), the DPO model demonstrates improvements as both a generator and verifier on AOKVQA, likely due to the dataset’s alignment with realworld images, which matches the nature of A-OKVQA.
Interestingly, while model ⑤ does not show improvements as a generator on ChartQA, it still produces positive results in best-of-N re-ranking, indicating that the learned preferences can generalize across domains.
However, weighted voting does not lead to any improvements, and no significant gains are observed in re-ranking for MathVision.
In contrast, when trained with reasoning data pairs, LLAVA-REASONER-DPO (⑥) shows improvements across both re-ranking metrics, underscoring the effectiveness of DPO on reasoning data pairs.
5.3 ADDITIONAL DPO COT PERFORMANCE ON GENERAL DATASETS
In table 7, we present the DPO CoT performance on OCRBench, MMStar, and MMMU.
We observe that both DPO models outperform the SFT baseline, with our DPO model trained on CoT reasoning pairs showing slightly better results.
In fig. 7, we further explore the effectiveness of DPO on the MMMU dataset, which consists of challenging college-level subject questions.
We provide reranking results for multiple-choice problems from the Dev+Val split (988/1050).
First, the SFT model with self-consistency shows consistent improvements reaching 45.5 with 64 candidate votes.
LLAVAREASONER-DPO, trained on reasoning data pairs, shows strong generalization on MMMU by excelling in both weighted voting and best-of-N voting during candidate re-ranking.
While the DPO model trained on RLAIF-V (⑤) improves CoT predictions, it does not achieve gains in the re-ranking metrics, indicating limitations in distinguishing correct from incorrect reasoning on more complex data.
We hypothesize that, compared to ChartQA, the reasoning questions in MMMU are more challenging and span a broader range of subjects.
The RLAIF-V dataset relies primarily on COCO image domain, which may not provide sufficient coverage, leading to weaker performance in re-ranking.
5.4 DPO CREDIT ASSIGNMENT
While the DPO model is trained on pairwise data, prior works (Rafailov et al., 2024; Lu et al., 2024) have shown that DPO policies can learn to predict token-level rewards from binary preference data.
These experiments primarily focused on math reasoning with LLMs.
In this work, we provide xamples of credit assignment learned by the VLM DPO, as shown in fig. 8.

The token-level DPO reward can be expressed as log π dpo( y(i) | x,V ) π sft( y(i) | x,V ) , where V represents the image, x the question, and yi the i-th token in the generated response.
This reward reflects the relative confidence of the DPO model compared to the SFT model for a given token in a candidate response.
In fig. 8, negative scores are shown in cool (blue) colors, while positive scores are shown in warm (orange) colors, with rewards normalized to a mean of 0.
On the left, we observe that the DPO model is particularly sensitive to errors during chart interpretation from the ChartQA dataset.
For instance, when the response incorrectly lists “Lamb” as “Beef” in a chart reading task, the DPO model assigns a highly negative score to this mistake.
On the right, we present examples from the AI2D dataset.
Here, a hallucination in the response, such as incorrectly stating that the left side of the moon is illuminated (the correct answer is the right side), receives a low score.
Additionally, when external knowledge is required to correctly identify the moon’s phase as “Crescent” instead of “Gibbous,” the DPO model penalizes the incorrect “Gibbous” answer with a negative score.
This indicates that the DPO model is more sensitive to knowledge-based errors than the SFT model, explaining its superior performance on CoT reasoning tasks in datasets such as AI2D.