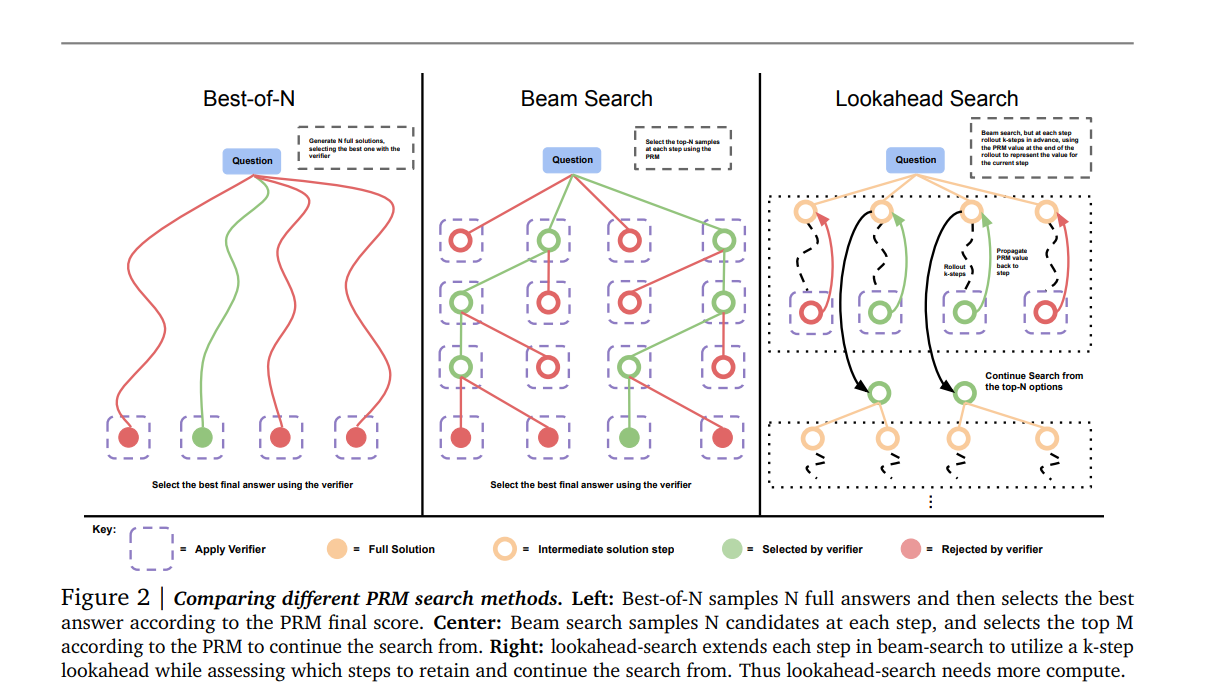
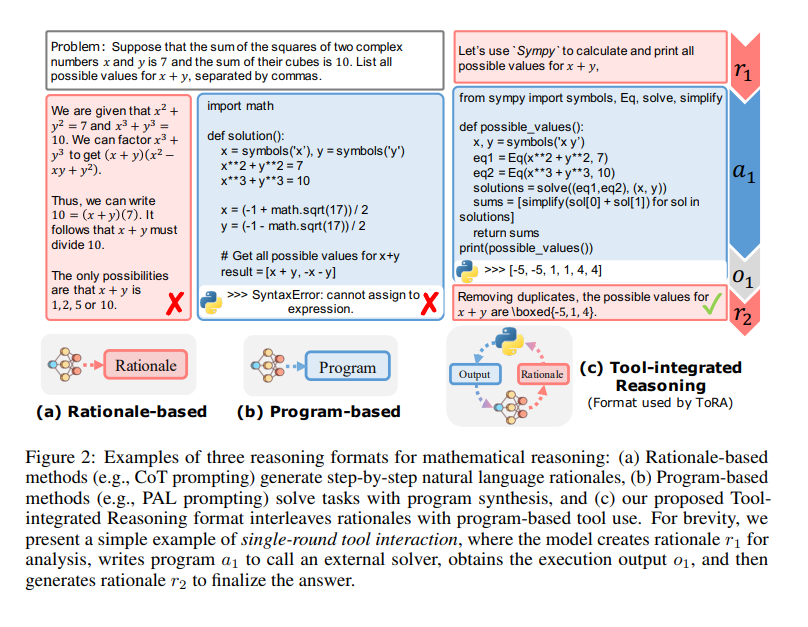
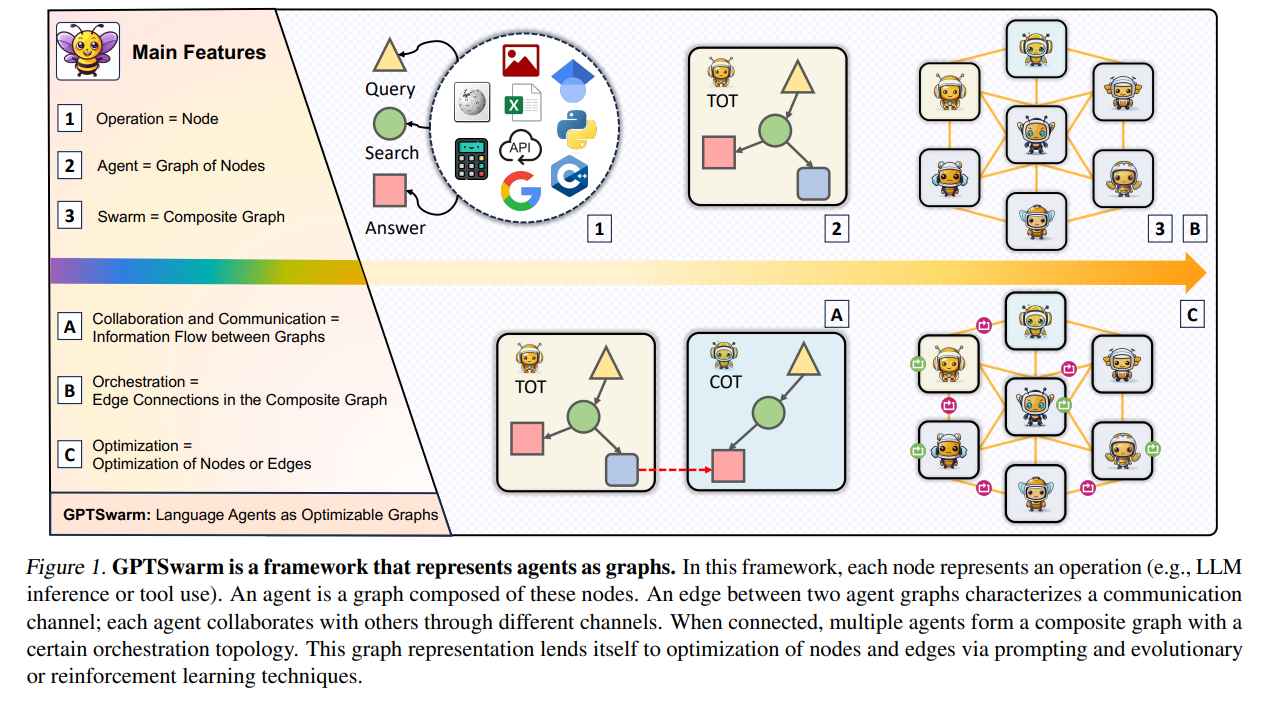
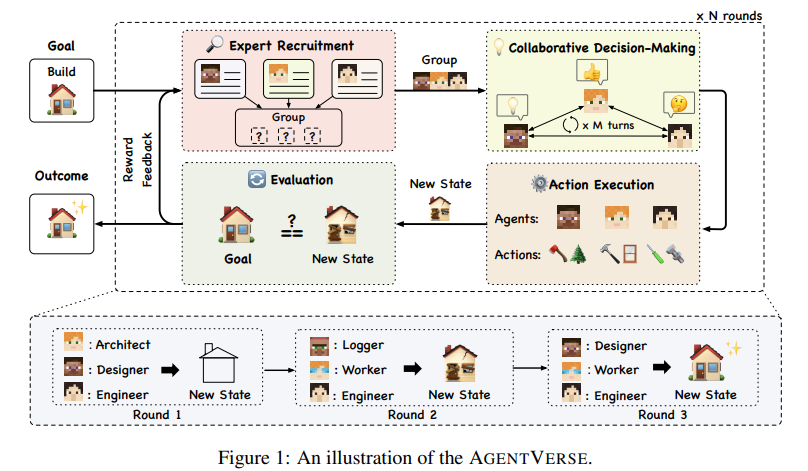
https://arxiv.org/abs/2408.03314(1) searching against dense, process-based verifier reward models; and(2) updating the model’s distribution over a response adaptively, given the prompt at test time. We find that in both cases, the effectiveness of different approaches to scaling test-time compute critically varies depending on the difficulty of the prompt모델 크기를 키우는 것과 test-time에 추가 계산을 수행하는 것 중 ..