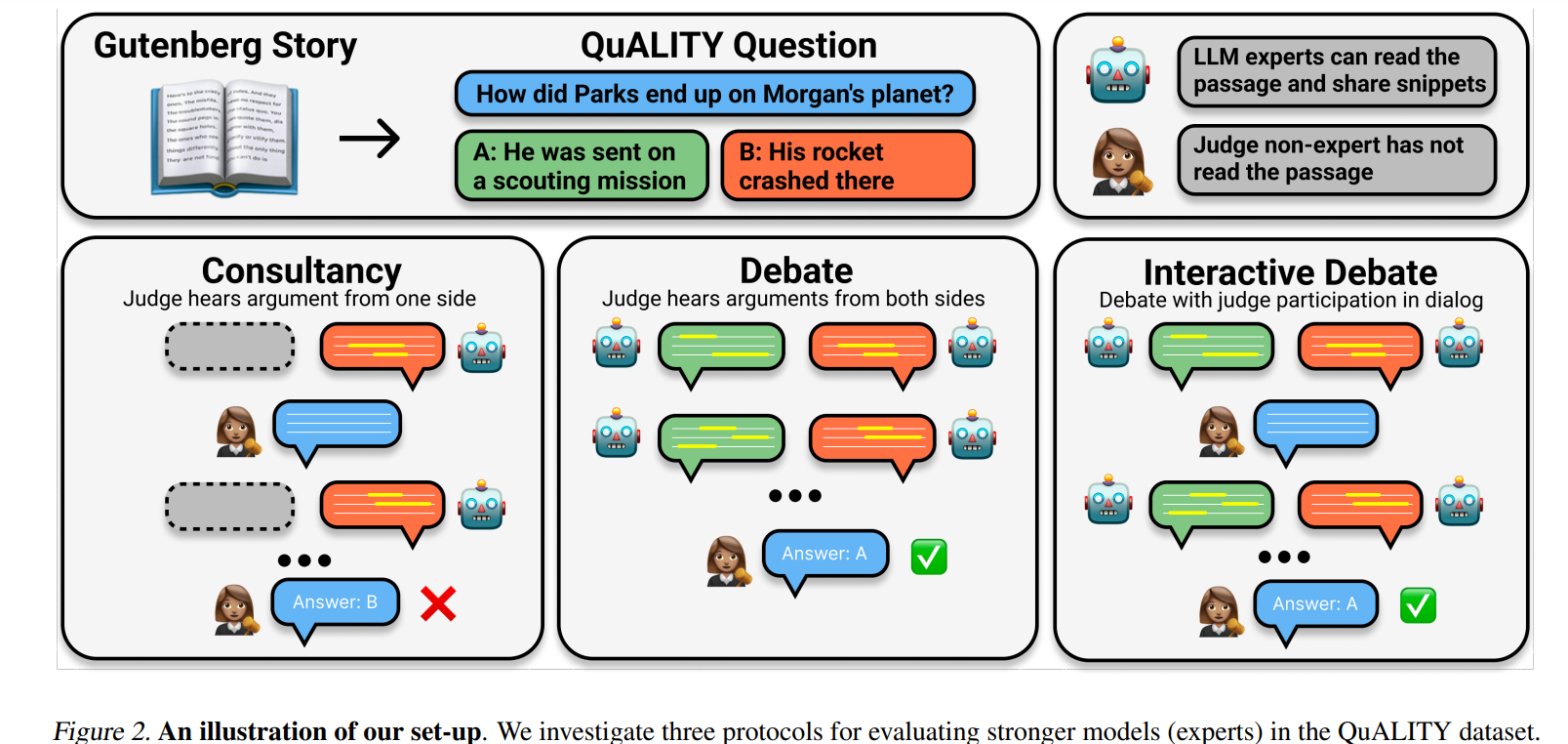
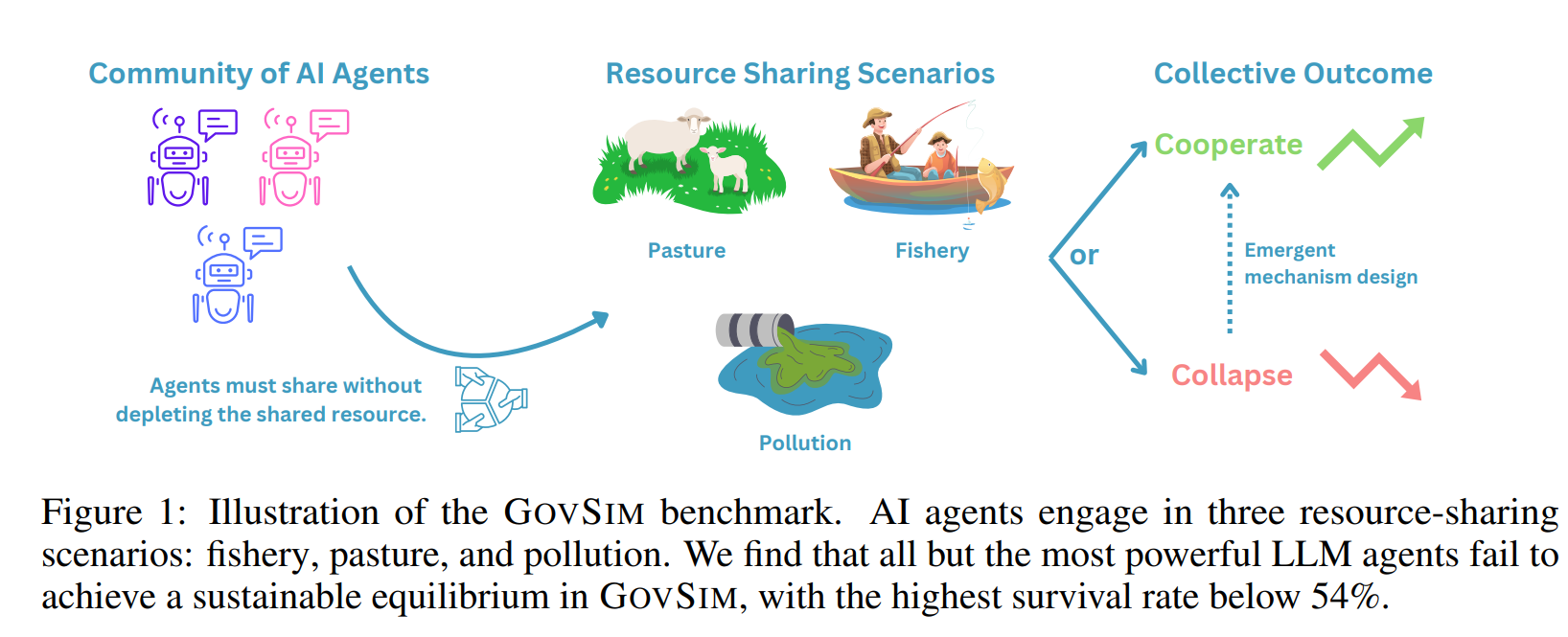
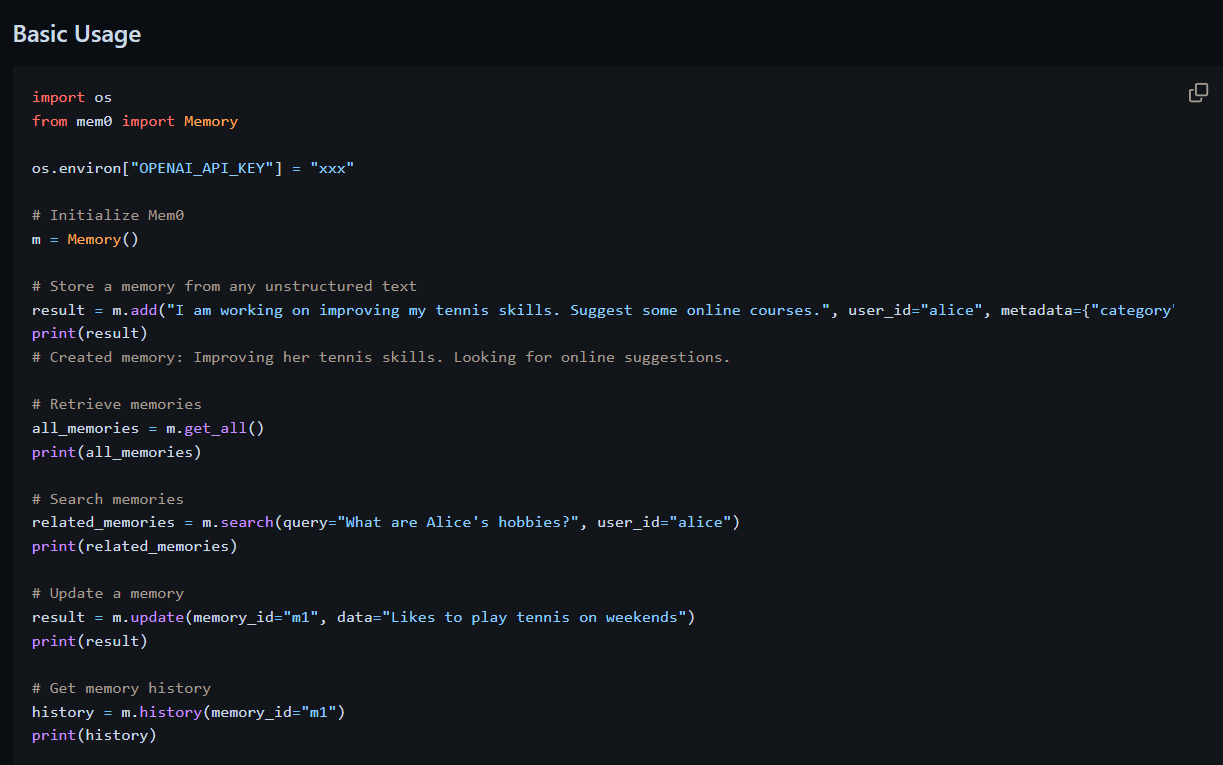
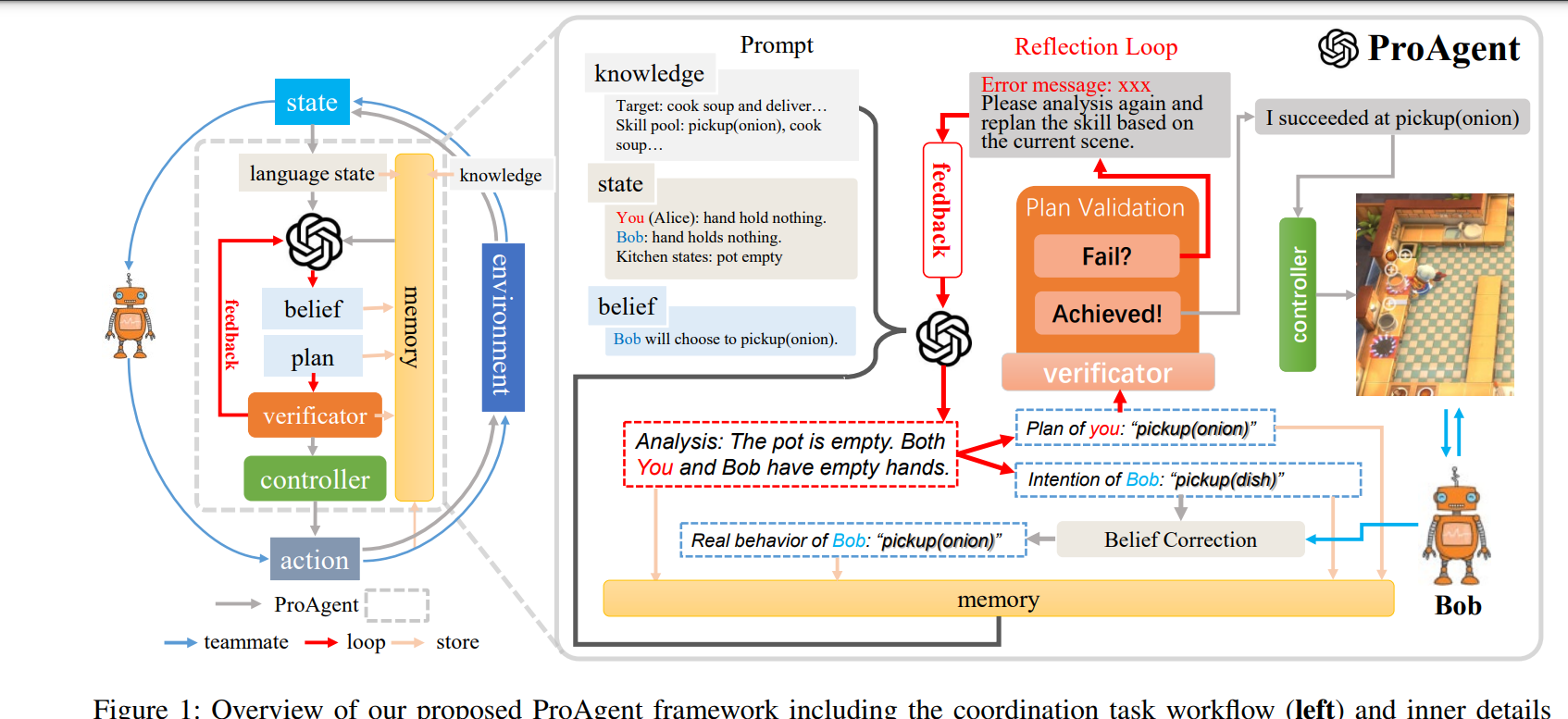
self-correcthttps://arxiv.org/abs/2211.00053https://arxiv.org/abs/2406.01297 When Can LLMs Actually Correct Their Own Mistakes? A Critical Survey of Self-Correction of LLMsSelf-correction is an approach to improving responses from large language models (LLMs) by refining the responses using LLMs during inference. Prior work has proposed various self-correction frameworks using different sources ..