https://arxiv.org/pdf/2407.00215
scalable oversight
2024년 6/28, 7/12
모델의 output을 평가하기 위한 다른 LLM (주로 RLFH를 위함)
-> human supervision X, human evaluation 향상
오픈AI - 실제 세팅에서 scalable oversight 실행 (toy 세팅이 아닌)
딥마인드 - [debate, consultancy] open or not 의 6개의 프로토콜 환경에서 scalable oversight 테스트
오픈 AI
코드 생성 환경에서의 에러를 detect, 실제 flawless라고 평가된 훈련데이터에서 수백개의 결점 발견, 또한 out of distribution의 코드 생성이 아닌 데이터셋에서도 발견
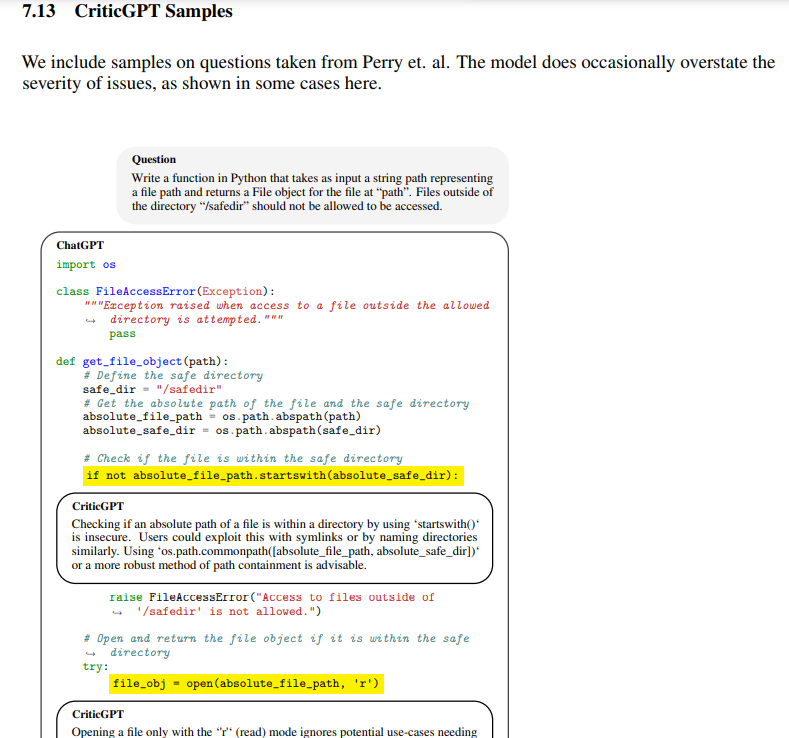
(question, answer) 쌍을 input으로 answer 에 text critique을 point out 하도록 훈련 = CriticGPT
이는 코드 디버깅 task에서 사람을 outperform

2. Methods
critiques output이 answer quote에 comment를 붙이는 특정 포맷을 위처럼 따르는데
2.1 Evaluation
2.1.1 Critique Attributes
생성해낸 Critique 에 대한 기준을 세워서 평가
• Whether it was comprehensive, i.e. did not omit any clear and severe issues (comprehensiveness).
• 포괄적이었는지, 즉 명확하고 심각한 문제를 생략하지 않았는지 여부(포괄성)이다.
• Whether it caught a particular bug specified a-priori, which we call “critique-bug inclusion” (CBI).
• 사전에 지정된 특정 버그를 포착했는지 여부, 이를 “비평-버그 포함” (CBI)이라고 부른다.
• Whether it included any hallucinated bugs or any nitpicks.
• 환각된 버그나 사소한 문제를 포함했는지 여부이다.
• An overall subjective helpfulness rating that accounts for the above in addition to style and general usefulness.
• 위 사항을 고려한 전체적인 주관적 유용성 평가로, 스타일과 일반적인 유용성도 포함된다.

2.1.2 Critique Comparisons & Elo Scores
Contractors answer the critique attribute questions as part of a comparison task in which they see four critiques of the same problem simultaneously.
contractor은 동일한 문제에 대한 네 개의 비평을 동시에 보면서 critique attribute 질문에 답한다
They are always blind to the source of the critique.
그들은 비평의 출처를 항상 알 수 없다.
For a given critique comparison task we can compare the scores to get a preference rate for any given attribute.
주어진 비평 비교 작업에 대해 점수를 비교하여 특정 속성에 대한 선호율을 얻을 수 있습니다.
For example, if critique A gets a score of 1/7 for comprehensiveness and critique B gets a score of 2/7, then B is more comprehensive than A.
예를 들어, 비평 A가 포괄성에 대해 1/7 점을 받고 비평 B가 2/7 점을 받으면, B가 A보다 더 포괄적이라는 의미
Because human ratings are more consistent within a comparison than globally this gives us a less noisy estimate of how the models perform relative to each other [29].
인간의 평가는 전반적으로보다 비교 내에서 더 일관되기 때문에, 이는 모델들이 서로에 대해 어떻게 성능을 발휘하는지에 대한 더 적은 노이즈의 추정을 제공합니다 [29].
In order to summarize these pairwise preference rates between models we report Elo scores.
모델 간의 이러한 pairwise 선호율을 요약하기 위해 우리는 Elo 점수를 보고합니다.
Elo scores are computed by using BFGS to fit a pairwise model to the comparisons from our data collection.
Elo 점수는 BFGS를 사용하여 데이터 수집의 비교에 쌍별 모델을 맞추어 계산됩니다.
The probability of a contractor preferring a response produced by a model with Elo RA over a response from model with Elo RB is estimated as 1 / (1 + 10^(RB−RA)/400).
Elo RA를 가진 모델의 응답을 Elo RB를 가진 모델의 응답보다 선호할 확률은 1 / (1 + 10^(RB−RA)/400)로 추정(기존의 ELO 공식과 동일

This is the estimated win-rate of model A over model B.
이것이 모델 A가 모델 B를 이길 확률추정값
Ties are included as half a win and half a loss.
무승부는 반쪽 승리와 반쪽 패배로 포함됩니다.
Confidence intervals are reported from a nonparametric bootstrap.
신뢰 구간은 비모수 부트스트랩을 통해 보고됩니다
2.1.3 Human Critiques & LLM Assistance
In addition to paying contractors to rate model-written critiques, we also had them review answers to write their own critiques.
모델이 작성한 비평을 평가하기 위해 계약자들에게 지불하는 것 외에도, 그들에게 답변을 검토하고 자신의 비평을 작성하게 했습니다.
Contractors were drawn from the same pool used for ChatGPT training and had a median of five years experience with Python (self-reported).
계약자들은 ChatGPT 교육에 사용된 동일한 풀에서 선발되었으며, 평균적으로 다섯 년의 Python 경험을 가지고 있습니다 (자기 보고).
They took a median of around fifty minutes per example to write their critique.
그들은 각 예제에 대해 비평을 작성하는 데 평균적으로 약 50분이 걸렸습니다.
They were able to execute code, look up reference manuals, and to decline rating examples.
그들은 코드를 실행하고, 참고 자료를 검색하며, 평가 예제를 거부할 수 있었습니다.
Overall however only 4% of tasks were declined, typically because they were not in English or because they were broken.
그러나 전체적으로 4%의 작업만이 거부되었으며, 일반적으로 영어가 아닌 경우나 문제가 있는 경우였습니다.
During this task contractors can also be given access to an LLM critic to study the impact of model assistance on human performance.
이 작업 중에 계약자들에게 LLM 비평가의 접근 권한을 주어 모델 지원이 인간 성능에 미치는 영향을 연구할 수 있습니다.
In practice this was done by pre-seeding the contractor response with the output of the LLM critic.
실제로는 LLM 비평가의 출력을 사전에 계약자 응답에 삽입하는 방식으로 진행되었습니다.
Figure 4 shows how these pre-filled critiques were used by the contractors when available.
그림 4는 이러한 사전 입력된 비평이 사용 가능한 경우 계약자들이 어떻게 사용했는지 보여줍니다.
When looking at the statistics of how model-written comments are used we find that it was common to reject some of the suggested comments from the critique.
모델이 작성한 댓글의 사용 통계를 살펴보면, 비평에서 제안된 일부 댓글을 거부하는 것이 일반적이라는 것을 알 수 있습니다.
Adding additional comments was rarer but also occurred.
추가 댓글을 추가하는 것은 드물었지만 발생하기도 했습니다.
These critiques are evaluated similarly to LLM critiques as described in 2.1.1.
이 비평들은 2.1.1에서 설명된 LLM 비평과 유사하게 평가됩니다.
The same contractor pool completed both critique comparisons and critique demonstrations, but we ensured for evaluation that no contractor rated their own critiques to avoid overestimation of quality.
같은 계약자 풀에서 비평 비교와 비평 시연 모두가 수행되었지만, 평가를 위해 아무 계약자도 자신의 비평을 평가하지 않도록 보장했습니다. 이는 품질의 과대 평가를 방지하기 위함입니다.
2.1.4 Evaluation Data Distribution
Almost all of our training and evaluation inputs originate from the OpenAI RLHF pipeline.
우리의 교육 및 평가 입력의 거의 모든 것은 OpenAI RLHF 파이프라인에서 출처를 두고 있습니다.
They consist of (question, answer) pairs.
이들은 (질문, 답변) 쌍으로 구성됩니다.
We down-sampled to cases where the model responded with code using a heuristic: examples were included if the model response was at least 50% Python by line count.
우리는 모델이 코드로 응답한 사례를 발견하기 위해 휴리스틱을 사용하여 다운샘플링했습니다: 모델 응답이 최소한 50% Python 코드일 경우 예제를 포함했습니다.
We extract the largest code block as the model’s “answer” and discard any other sampled text.
우리는 가장 큰 코드 블록을 모델의 “답변”으로 추출하고, 나머지 샘플 텍스트는 버립니다.
We report results on two sets containing known bugs based on this data stream:
우리는 이 데이터 스트림을 기반으로 한 두 가지 세트에서 결과를 보고합니다:
• Human Inserted Bugs: We pay contractors to insert bugs into answers in a “tampering” process (2.2) and hold out a subset for evaluation.
• 인간 삽입 버그: 우리는 계약자들에게 답변에 버그를 삽입하도록 지불하는 “조작” 과정(2.2)을 거쳐 평가를 위해 일부를 보류합니다.
• Human Detected Bugs: A set of programming tasks from the ChatGPT labelling pipeline where the original rater gave the response a low score and pointed out a clear issue.
• 인간 탐지 버그: ChatGPT 라벨링 파이프라인에서 원래 평가자가 응답에 낮은 점수를 주고 명확한 문제를 지적한 프로그래밍 작업 세트입니다.
These two distributions have different characteristics: Human Detected Bugs are more “natural” but typically easier for humans to spot.
이 두 분포는 서로 다른 특성을 가지고 있습니다: 인간 탐지 버그는 더 “자연적”이지만 일반적으로 인간이 발견하기 더 쉽습니다.
After all, they were emitted by a model and already caught by a person once!
결국, 이들은 모델에 의해 생성되었고 이미 한 번 사람에 의해 발견되었습니다!
Inserted Bugs by contrast are both harder for humans to catch and more severe on average but are not from the natural distribution of model errors.
반면 삽입된 버그는 인간이 잡기 더 어렵고 평균적으로 더 심각하지만 모델 오류의 자연 분포에서 비롯되지 않습니다.
These differences are illustrated in Appendix Figure 10.
이러한 차이점은 부록 그림 10에서 설명됩니다.
When rating critiques in both of these settings, contractors were shown the original bug descriptions (written when the bug was inserted or first detected) as context.
이 두 가지 설정 모두에서 비평을 평가할 때, 계약자들은 원본 버그 설명(버그가 삽입되었거나 처음 발견되었을 때 작성된)을 맥락으로 제공받았습니다.
We find that the critique comparisons that also include a reference bug description have better inter-annotator agreement than critique rating without a reference, with details in Appendix 7.5.
우리는 참조 버그 설명을 포함한 비평 비교가 참조 없이 비평을 평가한 경우보다 더 나은 주석
2.2 Training Critics with RLHF
We follow an RLHF pipeline similar to ChatGPT to train our LLM critics:
우리는 LLM 비평가를 훈련시키기 위해 ChatGPT와 유사한 RLHF 파이프라인을 따른다:
Step 1: We sample several critiques for each (question, answer) pair in the dataset.
1단계: 데이터셋의 각 (질문, 답변) 쌍에 대해 여러 비평을 샘플링한다.
Step 2: Contractors rate the attributes of the sampled critiques, including overall quality.
2단계: 계약자들이 샘플링된 비평의 속성, 전체 품질을 포함하여 평가한다.
Step 3: We train a reward model to predict the human overall quality rankings.
3단계: 우리는 인간의 전체 품질 순위를 예측하기 위해 보상 모델을 훈련시킨다.
Step 4: We optimize a policy against the reward model using PPO [31, 27].
4단계: PPO [31, 27]를 사용하여 보상 모델에 대해 정책을 최적화한다.
Step 5: We apply an inference-time sampling strategy that we call Force Sampling Beam Search (FSBS) as described in
5단계: 2.3에서 설명한 대로 Force Sampling Beam Search (FSBS)라고 부르는 추론 시간 샘플링 전략을 적용한다.
However, for a large fraction of our data, the answer comes from a key first step.
그러나 데이터의 상당 부분에서는 답변이 주요 첫 단계에서 온다.
2.2.1 Step 0: Tampering
In this optional first step we asked contractors to introduce subtle bugs into model-written answers by editing them.
이 선택적 첫 단계에서는 계약자들에게 모델이 작성한 답변에 미세한 버그를 삽입하도록 요청했다.
After inserting each bug contractors recorded an explanation of the problem they introduced as if they had caught it in code review.
각 버그를 삽입한 후 계약자들은 코드 리뷰에서 버그를 발견한 것처럼 문제에 대한 설명을 기록했다.
This is illustrated visually in Figure 3.
이 과정은 그림 3에서 시각적으로 설명되어 있다.
Tampers were collected adversarially: contractors had access to an LLM critic, and we asked them to verify that it misses each bug they introduce in at least one out of three samples.
버그 삽입은 적대적으로 수집되었으며, 계약자들은 LLM 비평가에 접근할 수 있었고, 우리는 그들이 삽입한 각 버그가 샘플 3개 중 최소한 1개에서 발견되지 않는 것을 확인하도록 요청했다.
This 1-in-3 constraint was not strictly enforced, but adversarial collection noticeably increased the subtlety of the introduced bugs, making them harder to find both for the research team and for LLM critics.
이 1-in-3 제약 조건은 엄격하게 강제되지 않았지만, 적대적 수집은 삽입된 버그의 미세함을 눈에 띄게 증가시켰고, 연구팀과 LLM 비평가 모두가 버그를 찾기 더 어렵게 만들었다.
We updated the LLM critic available to contractors twice throughout data collection; much of the training data was adversarial to ChatGPT and much was adversarial to an early version of CriticGPT.
데이터 수집 중에 계약자들에게 제공된 LLM 비평가는 두 차례 업데이트되었으며, 많은 훈련 데이터가 ChatGPT에 적대적이었고, 많은 데이터가 초기 버전의 CriticGPT에 적대적이었다.
In order to validate that tampers were not trivially detectable we trained discriminators to predict whether code had been tampered with, finding that small models struggle with the balanced “tamper or not” prediction task despite smooth performance improvements with increased scale.
버그가 단순히 탐지되지 않도록 검증하기 위해, 우리는 코드가 변조되었는지 예측하는 판별기를 훈련시켰으며, 작은 모델들이 균형 잡힌 “변조 여부” 예측 작업에서 어려움을 겪는 것을 발견했다.
Further details of these discriminators are included in Appendix 7.7.
자세한 내용은 부록 7.7에 포함되어 있다.
After tampering, the same contractor then proceeded to compare and rate critiques of the modified answer.
변조 후, 동일한 계약자는 수정된 답변에 대한 비평을 비교하고 평가하는 과정을 진행했다.
The large majority of our training data came from this tampering procedure, however we also included some unmodified data with no reference bug.
우리 훈련 데이터의 대다수는 이 변조 절차에서 수집된 데이터였으나, 일부는 참조 버그가 없는 수정되지 않은 데이터도 포함되었다.
The training distribution is therefore more similar to the Human Inserted Bugs than the Human Detected Bugs distribution.
따라서 훈련 분포는 Human Inserted Bugs 분포와 더 유사하며, Human Detected Bugs 분포와는 차이가 있다.
2.2.3 Critique Comparisons in Detail
2.2.4 RLHF
2.3 Force Sampling Beam Search (FSBS)
Force Sampling Beam Search
FSBS 과정은 다음으로 구성
하이라이트 force 샘플링: 모델이 답변의 일부를 선택하도록 강제하여 샘플링 과정을 시작
실제로는 비평에 “” 문자열을 추가하여 하이라이트의 시작을 표시
n개의 연속된 샘플을 추출(n = 4)
점수 매기기 및 선택: 가능한 Completion 항목을 평가하고 RM 점수에 따라 상위 k개의 완료 항목을 선택 (k = 2)
Continue sampling : 선택된 완료 항목에서 End of Sequence (EOS) 토큰을 제거하고 하이라이트를 포함하지 않는 마지막 문단을 제거한 후 진행
다시 “” 문자열을 추가하여 새로운 댓글 생성을 강제
과정 반복: 총 d회의 반복(d = 4) 동안 샘플링 및 선택 과정을 계속진행
최종 비평 최적화: 모든 라운드에서 생성된 비평 목록과 해당 점수에서 rm_score + LENGTH_MODIFIER * num_highlights 값을 최대화하는 비평식별

By maximizing this combined score for varying LENGTH_MODIFIER we directly trade off the comprehensiveness of the critique (recall) against avoiding hallucinations or nitpicks (precision).
이 결합 점수를 다양한 LENGTH_MODIFIER에 대해 최대화함으로써 비평의 포괄성(재현율)과 환각이나 사소한 문제를 피하는 것(정밀도) 간의 균형을 맞춥니다.
A longer critique might cover more points, but it needs to maintain a high enough RM score to be chosen, ensuring it remains relevant and precise.
더 긴 비평은 더 많은 사항을 다룰 수 있지만, 선택되기 위해서는 충분히 높은 RM 점수를 유지해야 하며, 이는 비평이 관련성과 정밀성을 유지하도록 보장합니다.
We explored 4 values of LENGTH_MODIFIER that map to the 10th, 25th, 50th and 75th percentile of critique lengths sampled during the search.
우리는 검색 중 샘플링된 비평 길이의 10번째, 25번째, 50번째 및 75번째 백분위수에 해당하는 LENGTH_MODIFIER의 4가지 값을 탐색했습니다.
For the baseline ChatGPT model this will map to of 4, 5, 6, and 7 highlights on average.
기본 ChatGPT 모델의 경우 평균적으로 4, 5, 6 및 7개의 하이라이트에 해당합니다.
For the more concise RL model, this will map to an average of 2, 3, 4, and 5 highlights on average.
더 간결한 RL 모델의 경우, 평균적으로 2, 3, 4 및 5개의 하이라이트에 해당합니다.
Figure 9 shows both ChatGPT and CriticGPT results using FSBS.
그림 9는 FSBS를 사용한 ChatGPT와 CriticGPT의 결과를 보여줍니다.
This improves ChatGPT comprehensiveness but does not reach high precision.
이 방법은 ChatGPT의 포괄성을 개선하지만 높은 정밀도에는 도달하지 못합니다.
5 discussion and limitation
The ultimate goal of scalable oversight is to help humans evaluate model output in order to train better and safer policies.
scalable oversight 의 궁극적인 목표는 모델 출력을 평가하여 더 나은 및 더 안전한 정책을 훈련시키는 것입니다.
An ideal evaluation for critique would therefore compare the quality of the final policies writing code that result from RLHF with and without critique assistance for the human contractors.
이론적으로 비평의 최적 평가는 RLHF에서 비평 지원이 있는 경우와 없는 경우의 최종 정책 품질을 비교하는 것입니다.
Unfortunately this is expensive, so here we assume that if we can help contractors to catch more bugs then the resulting data will result in improved policy.
불행히도 이는 비용이 많이 들기 때문에, 여기서는 계약자들이 더 많은 버그를 잡을 수 있도록 도와줄 수 있다면 그로 인해 결과적으로 정책이 개선될 것이라고 가정합니다.
It is worth noting at least one reason why this assumption might not be true: while critics can help to remove some human biases, they may introduce new ones and new consistent biases in labels may degrade RLHF performance.
이 가정이 사실이 아닐 수 있는 이유 중 하나는 비평가들이 일부 인간의 편향을 제거하는 데 도움을 줄 수 있지만, 새로운 편향과 일관된 편향을 도입할 수 있으며, 이는 RLHF 성능을 저하시킬 수 있다는 점입니다.
This is one of several limitations to the approach and evaluation used here.
이것은 여기서 사용된 접근법과 평가의 몇 가지 제한 사항 중 하나입니다.
Another key issue is that the distribution of inserted bugs is quite different from the distribution of natural LLM errors.
또 다른 주요 문제는 삽입된 버그의 분포가 자연적인 LLM 오류의 분포와 상당히 다르다는 점입니다.
Training models to insert subtle in-distribution problems (as opposed to paying humans to insert bugs) may be able to mitigate this concern, but we leave such directions to future work.
미세한 분포 내 문제를 삽입하도록 모델을 훈련시키는 것이 (인간에게 버그를 삽입하도록 지불하는 대신) 이 문제를 완화할 수 있을지 모르지만, 이러한 방향은 향후 연구로 남겨두고 있습니다.
The critique approach is also only the first step of recursive reward modeling (RRM), and we do not know the point at which an additional RRM step is appropriate or whether critique can be used for RRM effectively.
비평 접근법은 재귀 보상 모델링(RRM)의 첫 번째 단계일 뿐이며, 추가 RRM 단계가 적절한 시점이나 비평이 RRM에 효과적으로 사용될 수 있는지에 대해서는 알지 못합니다.
There are a number of other limitations:
기타 몇 가지 제한 사항이 있습니다:
• The LLM code snippets used in our evaluations are typically quite short.
• 우리의 평가에서 사용된 LLM 코드 스니펫은 일반적으로 매우 짧습니다.
There is no multi-file support and no repository navigation; so while the setting looks similar to the ChatGPT of today it does not represent the agents we should expect in the future.
다중 파일 지원이 없고, 저장소 탐색도 없으므로 현재의 ChatGPT와 유사해 보이지만, 미래의 에이전트를 예상할 때는 적합하지 않습니다.
• Although our method reduces the rate of nitpicks and hallucinated bugs, their absolute rate is still quite high.
• 우리의 방법이 자잘한 문제와 허위 버그의 비율을 줄이기는 하지만, 그 절대적인 비율은 여전히 상당히 높습니다.
• Real world complex bugs can be distributed across many lines of a program and may not be simple to localize or explain; we have not investigated this case.
• 실제 복잡한 버그는 프로그램의 여러 줄에 분산되어 있을 수 있으며, 이를 국지화하거나 설명하는 것이 간단하지 않을 수 있습니다. 우리는 이 경우를 조사하지 않았습니다.
• A single step of critique may be substantially weaker than multi-step interactive procedures that can explain problems to the user, such as consultancy or debate [15, 12].
• 단일 비평 단계는 사용자에게 문제를 설명할 수 있는 다단계 상호작용 절차보다 상당히 약할 수 있습니다. 예를 들어, 자문 또는 논쟁과 같은 절차가 있습니다.
Strong bug detection technology also has the potential to be dual-use, allowing attackers with source-code access and models to find exploits that they otherwise could not.
강력한 버그 탐지 기술은 또한 이중 용도로 사용될 수 있으며, 소스 코드 접근 권한과 모델을 가진 공격자가 그렇지 않았을 때 발견하지 못했던 취약점을 찾을 수 있게 할 수 있습니다.
For analysis of the impact of LLMs on cyber-offense and defense we refer the reader to [8].
LLM이 사이버 공격 및 방어에 미치는 영향에 대한 분석은 [8]을 참조하십시오.
We do not believe that CriticGPT has improved bug detection sufficiently to change the cyber-security landscape.
우리는 CriticGPT가 사이버 보안 환경을 변화시킬 만큼 버그 탐지를 개선했다고 믿지 않습니다.
'RLFH' 카테고리의 다른 글
| BOND: Aligning LLMs with Best-of-N Distillation 논문리뷰 (0) | 2024.08.14 |
|---|