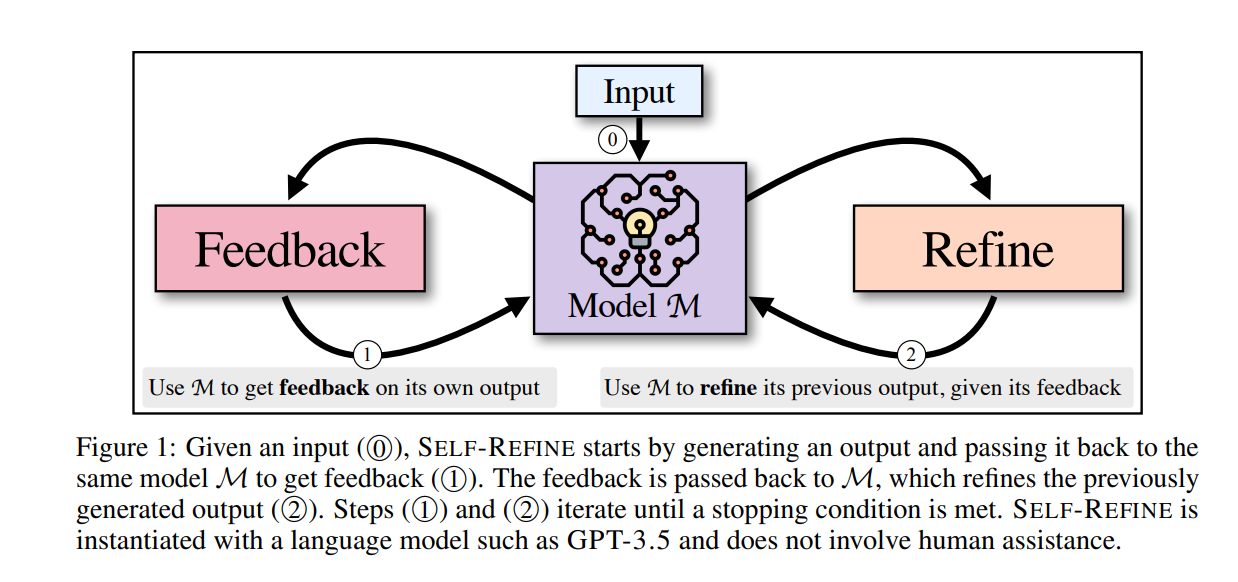
https://arxiv.org/abs/2406.06608 The Prompt Report: A Systematic Survey of Prompting TechniquesGenerative Artificial Intelligence (GenAI) systems are being increasingly deployed across all parts of industry and research settings. Developers and end users interact with these systems through the use of prompting or prompt engineering. While promptingarxiv.orgThe Prompt Report: A Systematic Survey ..