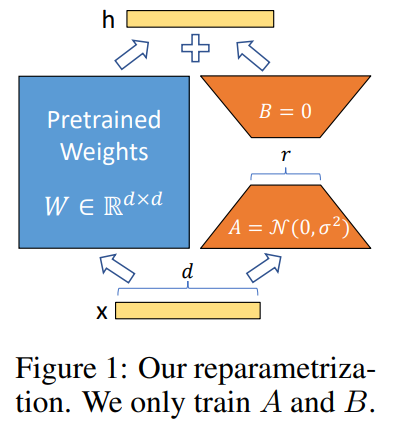
XAI , Interpretable AI1. AI 뿐 아니라 인간의 뉴런도 superposition hypothesis에 기반해 활성화될 것이 아닐까?2. LLM의 In-context learning(프롬프팅)이 가능한 이유3. chatgpt, Claude 의 뉴런서킷을 학습이 아닌 외부에서 직접 조정https://seongland.medium.com 요약 뉴럴넷에서 하나의 기능(feature)이 여러 뉴런에 나뉘어 존재하고 또, 하나의 뉴런이 여러 개의 기능을 담당하는 현상 = superposition hypothesis 여러 뉴런에 여러 기능이 있는 이유?뉴런 개수 > 기능의 개수?->?? (선형 대수의 관점)차원 개수보다 많은 기능이 존재한다는 게 말이 되는가? (e.g xy그래프에는 x와 y 값만..