vision language action 모델
VLA 모델의 가장 큰 문제점은 액션의 모달리티와 언어의 모달리티 사이의 mismatch 괴리가 있는 점이다.
이는 비디오에서의 자막 captioning (비디오,언어 모달리티와의 합성)과 유사한데
언어레벨의 액션 토큰은 매우 상당한 supervision을 필요로하고 모든 가능한 액션에 대해 정확히 묘사하지 못한다.
이를 위해 behavior trajectories 를 통한 어떤 액션, 즉 행동에 대한 결과에 대한 묘사(양질의 지식을)를 behaviour tokenizer로 학습을 해 이를 잘 연구되있는 vision, language (비젼, 언어) 토크나이져의 토큰화된 토큰과 결합한다. 이후 autoregressive model에 학습
이 behaviour trajectory에는 완전하고 다양한 behaviour가 표현되어 있어야하고 또 이 behaviour는 다른 모달리티와 양립가능해야함(mismatch x)

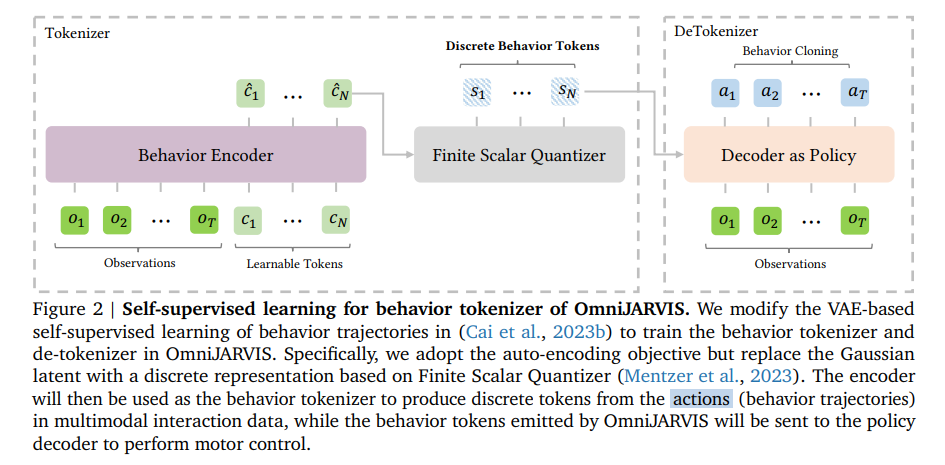
behaviour 인코더 - 액션을 토큰화시킴, imitation learning policy 디코더 = omnijarvis에 의해 생성된 behaviour 토큰으로부터 컨트롤 커맨드를 생성함
이전의 jarviscraft의 GROOT와의 차이점은 the Gaussian latent 를 a discrete representation based on Finite Scalar Quantizer 로 교체했다는점

π = policy 디코더(causal 트랜스포머), e = behaviour 인코더(non casual 트랜스포머), f = scaler quantizer 위의 그림을 수식화
behaviour trajectory의 최대 사이즈 T = 128
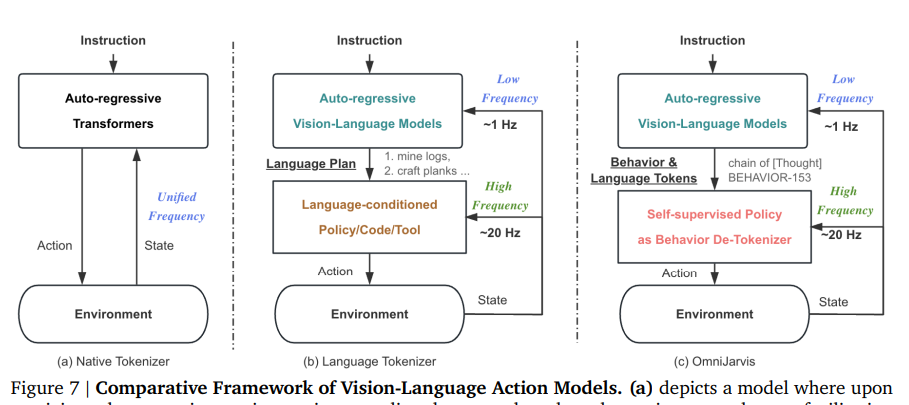
기존 VLA와의 차이
우리의 행동 토큰화와 비교했을 때, 대부분의 이전 VLA 모델 연구는 상호작용(o,a,o,a) 데이터의 행동 trajectory을 텍스트 설명으로 나타내고 별도의 conditioned controller를 호출하거나 (Wang et al., 2023b, c), 상태-행동 시퀀스 {𝑜0, 𝑎0, ...}를 Decision Transformers (DT)로 직접 표현했다 하지만 여기서는 멀티모달 상호작용 데이터에서 행동 부분을 보다 간결(quantizer를 통해)하면서도 여전히 정보가 풍부한 방식으로 표현한다. 또한 행동 출력, 즉 행동 토큰을 정책 디코더에 사용하는 것은 DT 스타일의 VLA 모델에서 직접 제어하는 것보다 더 효율적이다.

결국 behaviour trajectory로부터 n개의 behaviour 토큰을 생성해내는것이 목표인데
이를 위해 지금까지 behaviour 토큰을 생성했고
이제 학습을 진행할 데이터에는 instruction, memory, thought의 텍스트 프롬프트를 추가한다. 이는 인간의 사고방식을 흉내내기 위함 아래가 정확한
데이터의 형식이다 이 시퀸스를 토큰화 {𝑠0, . . . , 𝑠M} 시킨 뒤 이를처리해gradient descent 진행
loss function은 llm과 같고 thought behaviour를 결과물로 autoregressive하게 생성한다

하지만 이러한 데이터는 잘 없는데 특히 text 데이터를 만들기 위해 LLM을 사용한다. behaviour, bhv 데이터로 기존의 Minecraft contractor data의 OpenAI 의 데이터를 사용해 inst, mem, tht를 만든다 Visual Instruction Tuning 의 이전 선행연구 절차를 따라 진행한다 https://arxiv.org/pdf/2304.08485
Hugging Face의 TRL library의 SFTTrainer
1.4e-5의 학습률
cosine 스케쥴러
weight decay 는 0으로 warm-up ratio 는 0.03
FSDP를 사용하여 8개의 A800 GPU
배치 크기는 2
그래디언트 축적 단계는 4
bf16 정밀도
각 프레임 128x128 해상도에 각 에피소드를 여러 "트렁크(trunks)"로 분할, 각 트렁크는 128개의 프레임으로 구성되어 있다