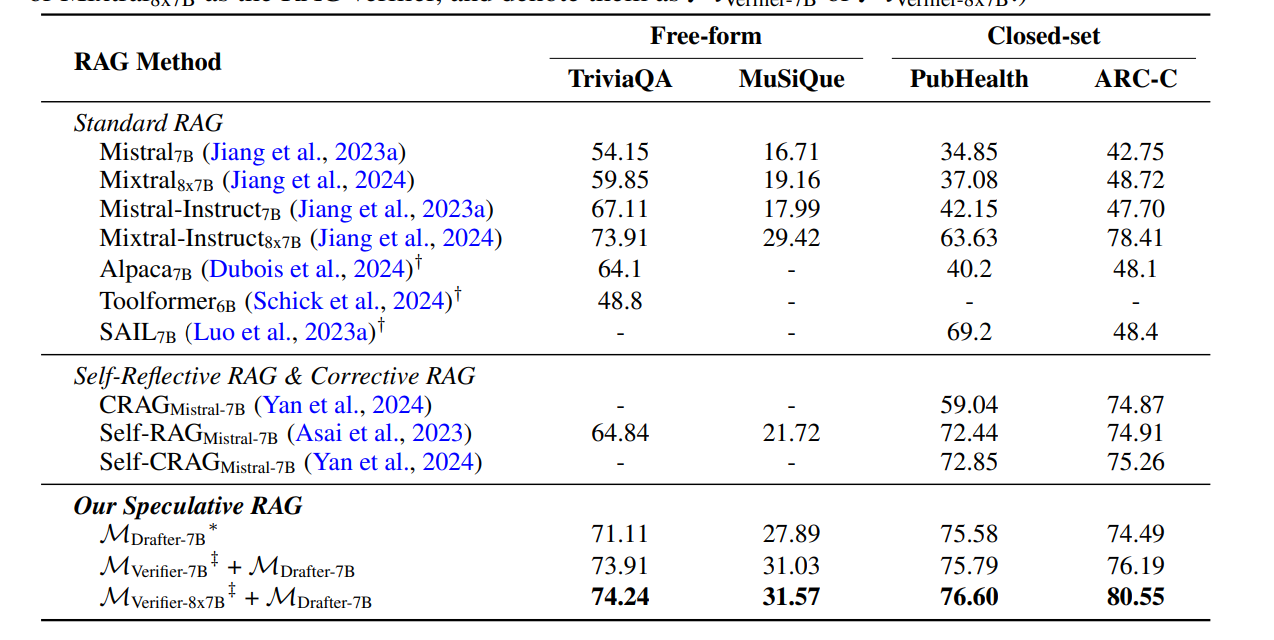
TriviaQA, MuSiQue, PubHealth, ARC-Challenge 벤치마크에서 SOTA 달성
RAG 시스템에 대한 기존 연구는 주로 retrieval 결과의 contextual 정보 품질을 향상시키는 데 집중하고 있지만, 이러한 시스템과 관련된 latency 지연관련 문제는 종종 무시한다
Query rewriting in retrieval-augmented large language models
Corrective RAG
self RAG
보통 refinement 반복과 별로의 instruction-tuning 등에 의존하기에 부가적인 훈련, 지연시간 증가를 필요로 하게 되는 것
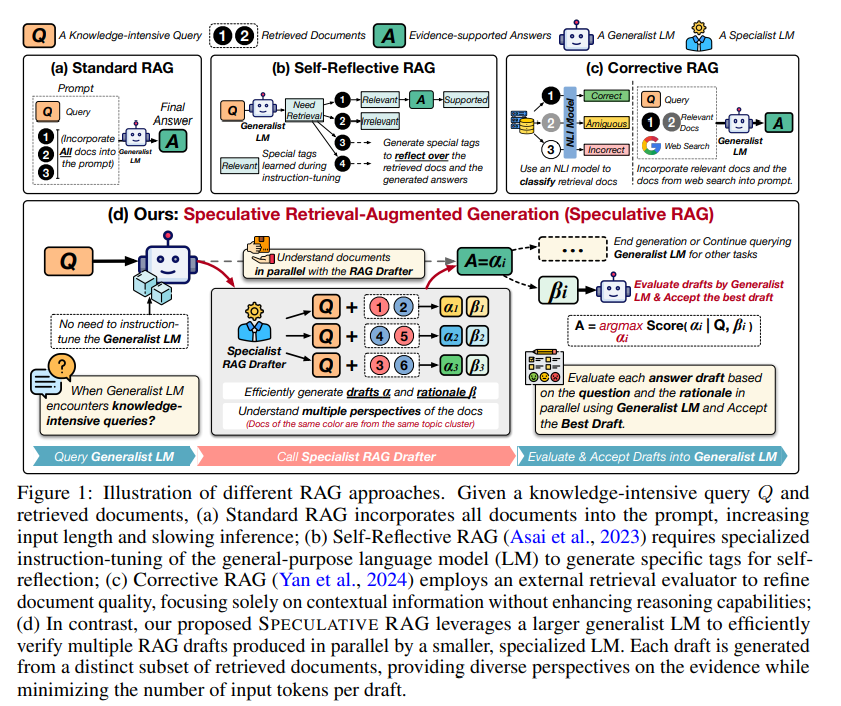
따라서 speculative decoding(작은 draft 모델)에 영감을 받은 RAG 프레임워크를 소개
SPECULATIVE RAG에서는 답변 후보를 draft하기 위해
1. 검색된 문서들을 subset(부분집합)으로 나눈다
2. 검색된(retrieved) 문서들을 내용 유사성(content similarity)에 따라 클러스터링하고, 각 클러스터에서 하나의 문서를 샘플링하여 부분집합(subset)을 형성함으로써 중복을 최소화하고 다양성을 최대화
3. 이렇게 만들어진 문서 subset들은 여러 개의 RAG 모듈 인스턴스(drafter - speculative decoding의 draft 모델)에 입력되어, 병렬로 초안 답변(draft answer)과 그에 상응하는 근거(rationale)를 생성
여기에 사용된 RAG 모듈(smaller, specialized)은 검색된 문서들에 대한 추론에 탁월하며 정확한 응답을 신속하게 생성할 수 있다. 이후, 일반화된 언어 모델(generalist LM)은 반복적인 문서들을 상세히 검토하는 과정을 건너뛰고, 대신 가장 정확한 답변을 결정하기 위해 근거(rationale)와 비교해 초안들을 검증하는 데 집중한다.

experiment EVAL
프롬프트 예시
rationale 생성 프롬프트

drafter 프롬프트

기존 RAG 프롬프트
