
기존의 related work
CoT- SC (여러개의 CoT 생성후 best를 선택)
ToT (LLM의 reasoning 과정을 tree형태로 모델링)
GoT
---------------------
사고의 다양한 과정을 사용, 또한 이전의 사고(thought)으로 backtrack도 가능하게함
하지만 사고라는 과정 자체를 rigid한 tree 구조에만 제한했다는 한계가 존재
이 연구에서 우리는 LLM의 사고가 임의의 그래프 구조를 형성할 수 있게 함으로써 근본적으로 더 강력한 프롬프팅을 달성할 수 있다고 주장
e.g)
이는 인간의 추론, 뇌 구조, 또는 알고리즘 실행과 같은 다양한 현상에서 동기를 얻었다.
새로운 아이디어를 작업할 때, 인간은 단순히 사고의 연쇄(CoT에서처럼)를 따르거나 서로 다른 별개의 사고(ToT에서처럼)를 시도하는 것이 아니라, 실제로 더 복잡한 사고의 네트워크를 형성할 것이다.
예를들어)
특정 reasoning chain을 탐색하고, 되돌아가서 새로운 것을 시작한 다음, 이전 chain의 특정 아이디어가 현재 탐색 중인 것과 결합될 수 있다는 것을 깨닫고, 두 가지를 새로운 해결책으로 병합하여 각각의 강점을 활용하고 약점을 제거할 수도 있다
GoT는 (G, T , E, R)로 모델링 될수 있느데
G는 LLM reasoning process
T는 thought transformations
E는 evaluator function
R은 ranking function
자세히 설명하면
GoT에서는 사고(thought)들이 점(vertices)로 선(edges)은 관계를(dependancy)를 나타낸다
G = (V, E) 가 현재 상태의 그래프고
Thought (G, pθ) = G′ = (V ′ , E′ ) 가 되는데 이와 함께 vertice, edge 또한 업데이트
e.g ) V ′ = (V ∪ V +) \ V −
(각 step마다 V와 V+를 합집합(∪) 그 다음, 이 합집합에서 V−를 제거(차집합, )

이 새로운 V(vertice)를 생성하기 위한 방법에는
1. Aggregation Transformations
2. Refining Transformations
3. Generation Transformations
가 있다.
이렇게 생성된 v가 좋은 사고(thought)인지 평가해야한다
Evaluation(v, G, pθ) = score
이를 통해 순위를 세울수 있다
v1, ..., vh = R(G, pθ, h)
h는 그냥 highest score thought 순서대로 h개 의미
예시)
글쓰기시
V에는 실제 paragraph, 혹은 paragraph작성에 대한 계획 등이 속할 수 잇는데 이를 class로 {plan, paragraph} 이런식으로 mapping

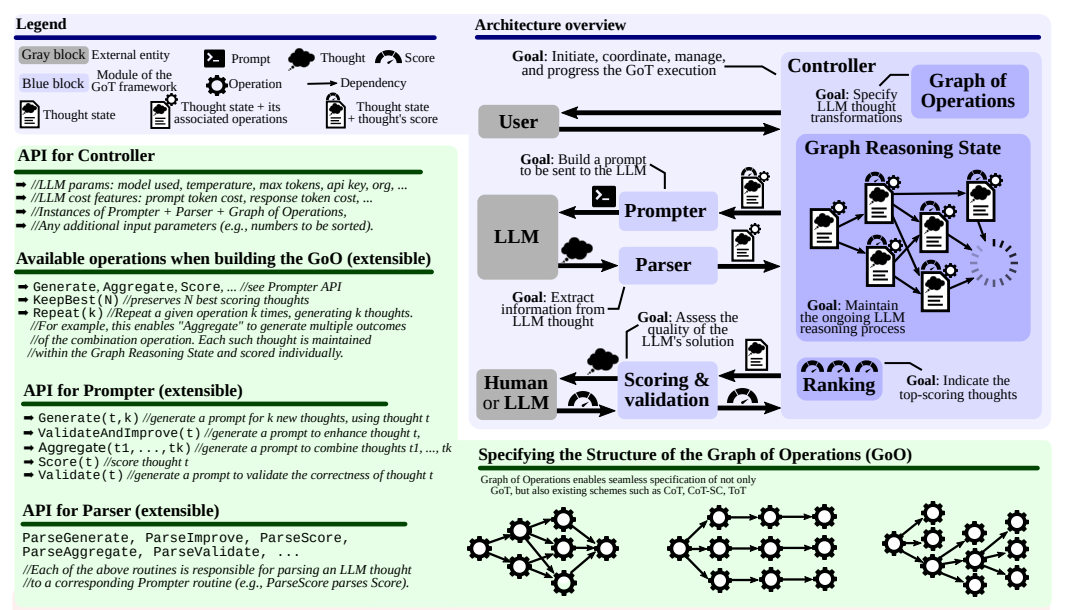
아키텍쳐
1. controller - transformation( 전체 reasoning 과정을 조정하고 진행 방향을 결정하는 역할)
2. parser - extractor
3. scoring module
4. prompter
controller는 2가지 요소를 가지고 잇는데
1. Graph of Operations (GoO)
정적 구조(static structure)
주어진 task의 그래프 decompose
즉, LLM 사고에 적용될 transformation을 추천( + order& dependency)
2. Graph Reasoning State (GRS)
동적 구조
현재 진행되는 LLM reasoning과정을 유지(maintain)
= 지금까지 한 사고(thought)와 그 state들의 기록관리




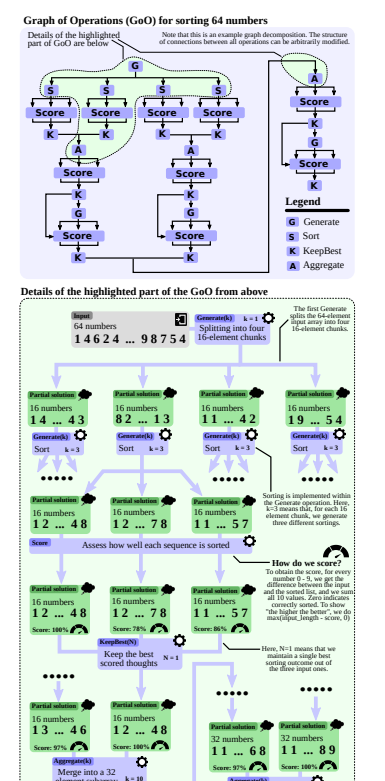
GoO:
1. Merge the 4 NDAs into a single one 5 times; Score each attempt and keep the best 3
2. Aggregate the merge attempts into a single one 5 times; Score each aggregation attempt and keep the overall best attempt (including Step 1)
3. Improve the merged NDA 10 times; Score each and keep the best







실제 github 코드



'inference-time, RLHF > search (language)' 카테고리의 다른 글
| Agent Q 논문리뷰: Advanced Reasoning and Learningfor Autonomous AI Agents (0) | 2024.08.17 |
|---|---|
| M* 논문리뷰 MindStar: Enhancing Math Reasoning in Pre-trainedLLMs at Inference Time (0) | 2024.08.17 |
| MUTUAL REASONING MAKES SMALLER LLMSSTRONGER PROBLEM-SOLVERS 논문 리뷰 (0) | 2024.08.17 |
| AlphaMath Almost Zero: Process Supervision Without Process 논문리뷰 (0) | 2024.08.16 |
| MCTS(monte carlo tree search) + LLM (0) | 2024.06.22 |