https://arxiv.orgs/pdf/2405.03553
중요한점
. The parameters of the linear layer associated with Vϕ1 are randomly initialized, leading to an initial tendency of the value head to predict a value close to 0 at the first (k = 1) round of MCTS. However, as the simulations in the first round MCTS proceed, the rewards (±1) from terminal nodes are back-propagated to their parent nodes. As simulations N gradually increase, the estimated values Qˆ of intermediate nodes converge towards the underlying true value within the range of [−1, 1].
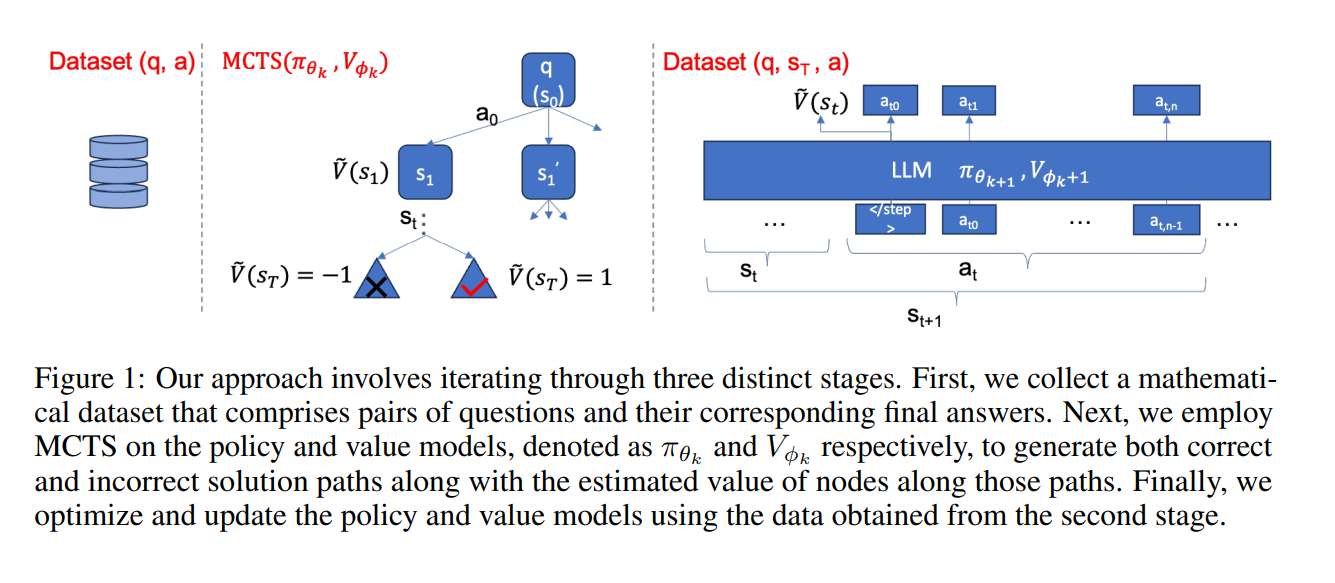



we incorporate a value model into the same LLM by appending a linear layer.
This advancement removes the necessity for timeconsuming rollouts for reward estimation.
While the LLM learns to solve mathematical problems from its own annotated solutions, the value model simultaneously learns how to assess the quality of intermediate reasoning steps from the corresponding state values in MCTS, just like humans.
we propose a step-level beam search strategy, where the value model is crafted to assist the policy model (i.e., LLM) in navigating more effective solution paths, as opposed to relying solely on prior probabilities
Compared to the greedy or MCTS inference strategies, the step-level beam search significantly enhances the LLM’s reasoning capability at a minimal cost.
final board state directly indicates a win or loss와 같은 알파고와 달리
our methodology requires validation of the equivalence between predicted answers and actual ones
Expansion
Back-tracing from the selected leaf node to the root forms a partial solution, serving as a prompt for further node expansions. In our case, given that the LLM can theoretically generate an unlimited number of potential actions (token sequence), 높은 temperature를 사용함으로써 다양성을 확보해서 확장
Evaluation
Evaluation of the leaf node or partial solution st, identified after the selection phase, is conducted by weighted sum as introduced in 알파고, gemini 논문





'inference-time, RLHF > search (language)' 카테고리의 다른 글
| Agent Q 논문리뷰: Advanced Reasoning and Learningfor Autonomous AI Agents (0) | 2024.08.17 |
|---|---|
| M* 논문리뷰 MindStar: Enhancing Math Reasoning in Pre-trainedLLMs at Inference Time (0) | 2024.08.17 |
| MUTUAL REASONING MAKES SMALLER LLMSSTRONGER PROBLEM-SOLVERS 논문 리뷰 (0) | 2024.08.17 |
| graph of thought 논문 리뷰 (GoT) (0) | 2024.07.19 |
| MCTS(monte carlo tree search) + LLM (0) | 2024.06.22 |