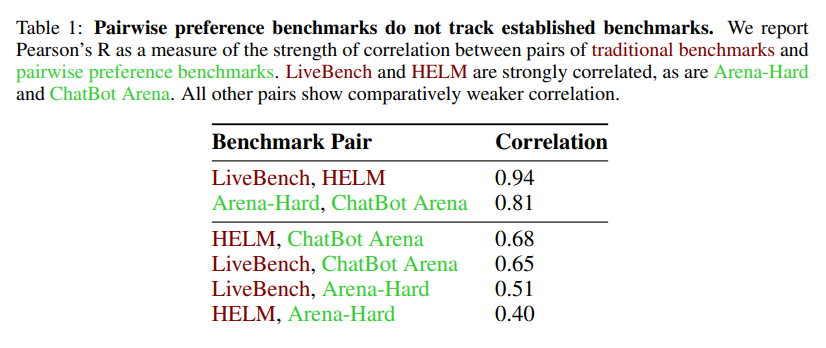
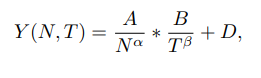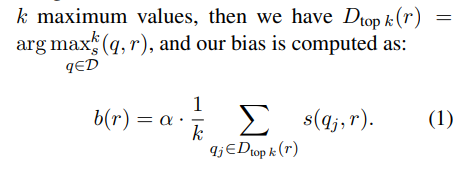https://arxiv.org/pdf/2411.03312https://github.com/locuslab/llava-token-compression.Let me format the text with line breaks for each sentence: Vision Language Models (VLMs) have demonstrated strong capabilities across various visual understanding and reasoning tasks. However, their real-world deployment is often constrained by high latency during inference due to substantial compute required to ..