https://arxiv.org/pdf/2406.08673
High-quality preference datasets are essential for training reward models that can effectively guide large language models (LLMs) in generating high-quality responses aligned with human preferences.
As LLMs become stronger and better aligned, permissively licensed preference datasets, such as Open Assistant, HHRLHF, and HelpSteer need to be updated to remain effective for reward modeling.
Methods that distil preference data from proprietary LLMs such as GPT-4 have restrictions on commercial usage imposed by model providers.
To improve upon both generated responses and attribute labeling quality, we release HelpSteer2, a permissively licensed preference dataset (CC-BY-4.0).
Using a powerful internal base model trained on HelpSteer2, we are able to achieve the SOTA score (92.0%) on Reward-Bench's primary dataset, outperforming currently listed open and proprietary models, as of June 12th, 2024.
Notably, HelpSteer2 consists of only ten thousand response pairs, an order of magnitude fewer than existing preference datasets (e.g., HH-RLHF), which makes it highly efficient for training reward models.
Our extensive experiments demonstrate that reward models trained with HelpSteer2 are effective in aligning LLMs.
In particular, we propose SteerLM 2.0, a model alignment approach that can effectively make use of the rich multi-attribute score predicted by our reward models.
HelpSteer2 is available at https://huggingface.co/datasets/nvidia/HelpSteer2 and code is available at https://github.com/NVIDIA/NeMo-Aligner.
3 Reward Model Training
We train reward models consisting of a base model and a linear layer that converts the final layer representation of the end-of-response token into five scalar values, each corresponding to a HelpSteer2 attribute.
The reward models are trained on top of the open-source Llama 3 70B base model and an in-house Nemotron-4 340B base model (described in Sec. 2.1).
For each model, we train for two epochs using HelpSteer2 data, with a global batch size of 128.
We select the top checkpoints with the lowest validation loss for evaluation.
We train with a MSE loss function, a constant learning rate on each model (70B: 2e-6, 340B: 7e-7) using an AdamW optimizer [32] and 10 warmup steps, following a LR search (70B: {1,2,3,4,5}e-6; 340B: {1,3,5,7,9}e-7).
For comparison, we also trained a Llama 3 70B base model separately using 1 epoch of HH-RLHF [2]; 1 epoch of Open Assistant [11] or 2 epochs of HelpSteer [12] (to approximately match for difference in dataset size) using the same hyper-parameters.
Evaluation
Following [33, 34], we evaluate the trained reward models using Reward Bench [14] excluding the optional Prior Sets category which we report separately (with detailed reasons in Appendix H).
Reward Bench comprises 2985 diverse tasks, each consisting of a prompt, a chosen response, and a rejected response.
Task accuracy is calculated based on whether the chosen response receives a higher reward than the rejected response.
The tasks in Reward Bench are categorized into four main categories: Chat, Chat-Hard, Safety, and Reasoning. Overall accuracy is determined by taking the mean of each category.
Details for evaluation are in Appendix H. We choose to use RewardBench due to its diversity of tasks (4 categories and 23 sub-categories), which minimizes the likelihood of overfitting.
With over 80 models on the leaderboard [35] available for comparison, it serves as a well-trusted benchmark.
Results
Overall, reward models trained with HelpSteer2 perform well on Reward Bench, achieving state-of-the-art numbers compared to proprietary models and those trained with data allowing permissive use.
This is particularly noteworthy given that HelpSteer2 consists of only 10k response pairs.
Llama 3 70B trained on HelpSteer2 (88.8% Overall) outperforms all other models trained with data allowing permissive use by >9.7%, including the same Llama 3 70B base model trained with Open Assistant, HH-RLHF or HelpSteer.
Scaling up the base model to Nemotron-4 340B with the same dataset results in the trained reward model topping the Reward Bench primary leaderboard with an overall performance of 92.0%.
This suggests that as more capable base models emerge, training them with HelpSteer2 can lead to more powerful reward models.
Beyond the high quality of the dataset, we attribute this high performance to the data efficiency of the SteerLM Reward Model training.
Unlike preference-based training, SteerLM Reward Model training predicts the scalar value of the response's rating (a float ranging from 0 to 4) for each finegrained aspect: Helpfulness, Correctness, Coherence, Complexity, and Verbosity.
This approach provides more information to the reward model [12] compared to simple binary preferences, making it clearer what constitutes a "good" response.
For instance, binary-trained reward models might sometimes incorrectly associate "goodness" with artifacts like response length, as statistically, longer responses tend to be more helpful, though this is not always accurate [37, 38].
In contrast, SteerLM RMs explicitly train the model to predict the verbosity of a response, enabling it to disambiguate verbosity from the overall quality of the response.
In addition, for Bradley-Terry-style preference reward models, the reward values can only be compared against responses to the same prompt.
We can construct a new reward r ′ = r + f(x) which is equivalent to the original Bradley-Terry (BT) reward r, where the f(x) can be any function of prompt x.
The reward offset is different for different prompts which causes difficulty of doing model alignment as we do not explicitly consider the offset difference of the different prompts in the training loss.
This means that a response with reward 4 for one prompt is not necessarily better than a response with reward 2 for another prompt as scored by BT Preference RMs, while it is the case for SteerLM Regression RM.
Relative to other models, those trained with HelpSteer2 perform exceedingly well in the Chat-Hard category, surpassing the second-best by 6.5%.
This is because HelpSteer2 is primarily aligned with the task of distinguishing between good and excellent responses.
Chat-Hard is likely the most relevant metric for preference learning with capable domain-general LLMs since we typically start with a good model and aim to improve its responses further.
Unexpectedly, models trained with HelpSteer2 also show good performance in the Safety and Reasoning categories, even though HelpSteer2 does not explicitly focus on these aspects.
This may be due to an implicit association between helpful responses and general safety, and transfer learning between being factually correct and reasoning tasks.
However, HelpSteer2 trained models do not surpass the Reasoning performance of the strongest alternative models, which are trained on specific reasoning datasets, such as UltraInteract [34].
Finally, HelpSteer2 trained models substantially under-perform many other models on Prior Sets, likely because those other models were trained on the training subsets of these Prior Sets [33].
4 Aligned Models
We demonstrate three approaches for using the Llama 3 70B Reward Model to align LLMs: Iterative Direct Preference Optimization (Iterative DPO), Proximal Policy Optimization (PPO) and SteerLM.
4.1 Evaluation
Following HelpSteer [12], we use MT Bench [31] to measure helpfulness, TruthfulQA MC2 [39] to measure correctness, and the mean number of characters in MT Bench responses to measure verbosity.
However, instead of the GPT-4-0613 judge used in HelpSteer [12], we use GPT-4-0125-Preview (Turbo) as a judge because we find that it is a stronger model and better suited as a judge.
In addition, we also use AlpacaEval 2.0 Length Controlled [40] and Arena Hard [41] as secondary measures of helpfulness, following [33, 42].
MT Bench is also referenced as a validation metric for checkpoint selection.
Details for each evaluation metric is available in Appendix H.
4.2 SFT
Following HelpSteer [12], we train a Llama 3 70B Base model using only Open Assistant [11] with 56k conversations for 2400 steps with a global batch size of 128 (close to 4 epochs).
We use a constant learning rate (LR) of 2e-6 using the AdamW optimizer after searching LR in {1,2,3,4,5}e-6, saving a checkpoint every 200 steps.
This represents the SFT model trained on existing open-sourced data only.
However, we find that a SFT model trained with only Open Assistant is weak compared to the Llama 3 70B Instruct, likely due to the inconsistent quality of the responses it contains.
Therefore, we trained another model using an SFT dataset (named 'Daring Anteater') consisting of 100k conversations, each averaging 2.88 model turns.
Approximately 93% of the data are synthetically generated following a similar pipeline as [43] by replacing OpenAI models with an earlier aligned version of Nemotron-4 340B and Mixtral-8x7B-Instruct-v0.1 [9], while the rest comes from ARB [45], SciBench [46], tigerbot-leetcode [47], PRM800K [48], FinQA [49], and wikitablequestions [50].
We trained this model using identical hyper-parameters except training it for 1600 steps with a global batch size of 384 (close to 2 epochs), given the larger size of the dataset.
All models on DPO and PPO are trained starting from this model.
4.3 DPO
We first performed DPO training on the SFT model from Sec. 4.2.
To do this training, we converted our HelpSteer2 train set into a preference dataset by taking the response with the higher helpfulness score as the chosen response, with the remaining response being the rejected response.
In cases where the helpfulness scores were identical, we discarded that pair entirely.
This became our HelpSteer2 DPO dataset, which contains 7,221 training samples.
We then performed DPO training on this data for 7 epochs using a constant LR of 2e-7, Kullback–Leibler (KL) penalty of 1e-3, AdamW optimizer, Global Batch Size 128, and Weight Decay 0.1.
Optimal LR was identified following a search among {3e-7, 2e-7, 1e-7, 9e-8} and KL penalty following a search among {1e-3, 4e-4}.
We evaluated checkpoints once every 25 steps.
We then performed Iterative DPO [33] on this model by utilizing 20k prompts from the Daring Anteater SFT dataset and generating 10 responses per prompt (temperature=0.7, top-p=0.9).
These responses were then scored by the Llama 3 70B Reward Model (Sec. 3) and a pairwise preference dataset generated by taking the highest and lowest goodnessscore for the chosen and rejected, respectively.
The goodness score is a scalar based on 0.65*helpfulness + 0.8*correctness + 0.45*coherence, which we find to give best differentiation between chosen and rejected responses in RewardBench prompts.
We then performed DPO training on this data for 3 epochs using similar hyper-parameters as above, except KL penalty of 1e-3 and LR of 9e-8, following similar hyper-parameter search.
4.4 PPO
We performed PPO on the SFT model we trained in Sec. 4.2 using HelpSteer2 prompts as well as the Llama 3 70B Reward Model (Sec. 3).
The reward was calculated using goodness score (Sec. 4.3), followed by taking away the mean of the HelpSteer2 responses and dividing it by its standard deviation.
We trained PPO using a global batch size of 128, a rollout buffer of 128 and a constant LR of 1e-7 and KL-penalty of 3e-3, after searching LR in {1,2,3,4,5}e-7 and the KL-penalty in {1,2,3,4,5}e-3.
We train for 64 steps and evaluate a checkpoint every 4 steps.
The generation stage of PPO is optimized using NeMo-Aligner's integration of TensorRT-LLM [26].
4.5 SteerLM
Overview SteerLM [12, 18] aligns language models by steering them towards generating outputs with desired attribute values by conditioning on various attributes during training.
We trained the SteerLM model following [12]. Specifically, we used the Llama 3 70B Reward Model to annotate the Daring Anteater SFT dataset (Sec. 4.2), followed by attribute-conditioned supervised fine-tuning of a language model on the annotated dataset to generate responses conditioned on target attribute scores.
However, the original SteerLM method does not explicitly enforce the generated responses to follow the desired attribute distribution conditioned on during training.
To address this limitation, we propose SteerLM 2.0, which iteratively trains the model to approximate the optimal SteerLM policy constructed by the reward model.
This is achieved using the original SteerLM trained model to generate multiple sampled responses and then using a KL divergence loss between current policy and optimal SteerLM policy to guide the model towards generating a response that is more reflective of the desired attribute values.
SteerLM 2.0 can be conducted in iterations (n=2) using the optimized policy after each iteration to sample responses and train an improved policy.
In each iteration, we sampled multiple diverse responses (n=10, temperature=0.7, top-p=0.9) from 20,000 different prompts from the Daring Anteater SFT dataset.
SteerLM 2.0 is trained for 2 epochs with AdamW optimizer constant LR 1e-7 and global batch size 128.



Inference Attributes In theory, we need to sample various attribute combinations. In this paper, we focus on to calibrate the model to generate good responses, so we choose to focus on one set of desired attributes for response sampling. Because HelpSteer2 responses are much (around 3x) longer and more complex than in HelpSteer [12], we found that using Complexity 2 and Verbosity 2 as default leads to more better generations than setting them both to 4, as done in HelpSteer [12]. The other three attributes (Helpfulness, Correctness and Coherence are set to 4, as in HelpSteer [12].
Optimal SteerLM Conditional Distribution From the Reward Assumes that we have trained a SteerLM reward model that can predict the attributes a based on the prompt x and response y. It outputs the conditional probability P(a|x, y). Using Bayes’ rule, the optimal SteerLM model is the probability distribution of y given the prompt x and attributes a:
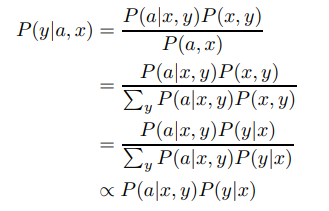
Equation 1 shows that we can construct an optimal SteerLM model by reversing the SteerLM reward model using Bayes’ rule.
The prior distribution P(y|x) can be approximated by training a separate language model to generate y given prompt x. Approximated SteerLM Conditional Distribution Assume we have an approximated SteerLM model Qθ(y|a, x) parameterized by θ. We can measure its distance from the optimal P(y|a, x) by the KL divergence

If the training data (a, x, y) matches the distribution P(x)P(a)P(a|y, x)P(y|x), then optimizing Equation 3 is reduced to Supervised Fine-tuning loss. However, in general this is not the case, and we need to sample y from distribution P(x)P(a)P(a|y, x)P(y|x). We propose to sample responses y from an original SteerLM model Q′ (y|a, x) to make the loss estimation in Equation 3 more sample efficient:

Practical Gradient Estimation To optimize Equation 4, we use gradient descent which requires estimating: 생략
Overall
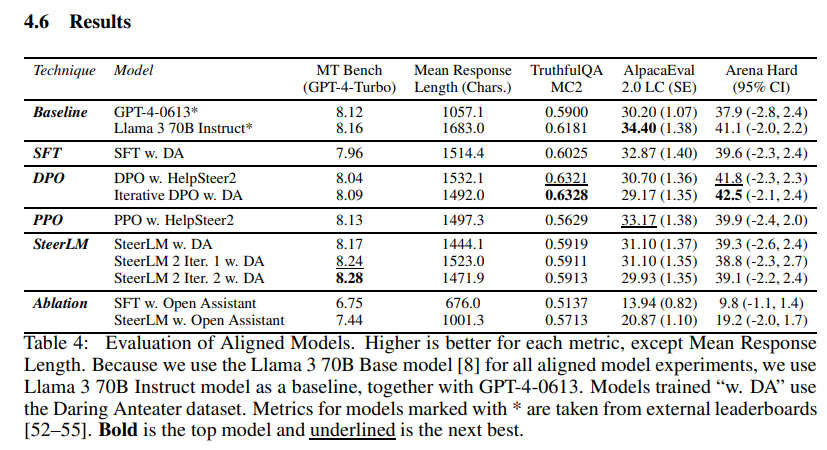
Across all metrics, at least one model trained using the Llama 3 70B Reward Model matches (i.e. within standard error) or exceeds the performance of Llama 3 70B Instruct, a model which has been trained with 10 million samples across SFT and preference-based training [56].
Compared to the undisclosed, data-hungry alignment recipe of Llama 3 70B Instruct, our alignment recipe is transparent and substantially more data efficient, requiring only 10 thousand HelpSteer2 preference pairs and 100 thousand SFT samples.
This represents only 1% of the amount of data using for training Llama 3 70B Instruct.
In addition, our models exceed the performance of GPT-40613 across all metrics, a notable yardstick representing frontier models from a year ago.
DPO model is most outstanding in terms of TruthfulQA [39] and Arena Hard[41].
We find that most of its performance comes from DPO using the HelpSteer2 dataset, while Iterative DPO gives a further boost.
The benefit of using HelpSteer2 for DPO comes from the selection of chosen and rejected pairs based on the helpfulness of the responses.
Because Helpfulness has a Pearson correlation of 0.943 with Correctness in HelpSteer2 (Table 2), DPO with HelpSteer2 helps the model to differentiate between right and wrong answers.
This is useful for improving TruthfulQA MC2, which focuses on choosing among correct and incorrect options.
Similarly, Arena Hard contains mostly (>50%) knowledge-intensive coding problems that require the model to accurately answer.
PPO model performs the best in terms of AlpacaEval 2.0 LC.
This is likely because AlpacaEval 2.0 mostly contains simple prompts containing only a single requirement (e.g. "How do I wrap a present neatly?" and "What are the best exercises for beginners?").
Therefore, they are typically less about whether models can answer them accurately (since most models can) as whether it can answer with sufficient levels of details without being too verbose (which is penalized by the LengthControl aspect in AlpacaEval 2.0).
Therefore, PPO can minimally improve the style of the response (vs. the SFT model).
However, similar to [57], we observe a severe degradation in TruthfulQA with PPO.
We suspect this is due to the low representation of Multiple-Choice-Questions (MCQ) in the HelpSteer2 prompts, leading the policy to drift off in a direction that reduces MCQ performance.
SteerLM model performs optimally on MT-Bench.
MT Bench represents complex instructions containing several requirements as well as follow up questions (e.g. "Craft an intriguing opening paragraph for a fictional short story.
The story should involve a character who wakes up one morning to find that they can time travel." followed by "Summarize the story with three bullet points using only nouns and adjectives, without verbs.").
SteerLM does well likely because given that the model is trained using one prompt paired with ten sampled responses that are mostly similar with each other but have some minor differences that affect their reward as scored by the Llama 3 70B Reward Model.
SteerLM training seeks to improve the likelihood of the best responses while averting mistakes made by other responses.
This is useful for MT Bench since each prompt contains many different requirements, which requires a fine-level, multi-to-one contrastive learning beyond imitation learning (SFT), contrastive learning between chosen/rejected (DPO) and single sample rollout (PPO).
Ablation
A large proportion of our model's performance comes from the Daring Anteater SFT dataset.
If we do only SFT with Open Assistant[11], following HelpSteer paper [12], MT Bench substantially drops from 7.96 to 6.75, as do other metrics.
Nonetheless, even if only Open Assistant is used, using the Reward Model can massively boost the performance (MT Bench from 6.75 to 7.44), and surprisingly by a larger margin than when using Daring Anteater (MT Bench from 7.96 to 8.28).
This is likely because Daring Anteater responses are mostly of high quality as they are mostly generated by a strong LLM (Nemotron-4 340B) whereas Open Assistant is crowd-sourced with a wide variety of quality in responses.
This suggests our Reward Model can improve final model performance, regardless of initial performance.