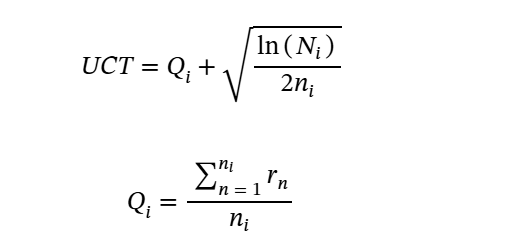https://arxiv.org/html/2502.01618v3#S3 A Probabilistic Inference Approach to Inference-Time Scaling of LLMs using Particle-Based Monte Carlo MethodsWe now zoom in on how PF scales with inference-time compute. Figure 2 shows the change of performance (in terms of accuracy) with an increasing computation budget (N=1,2,4,8,16,32,64,128𝑁1248163264128N=1,2,4,8,16,32,64,128italic_N = 1 , 2 , 4 , 8 , ..