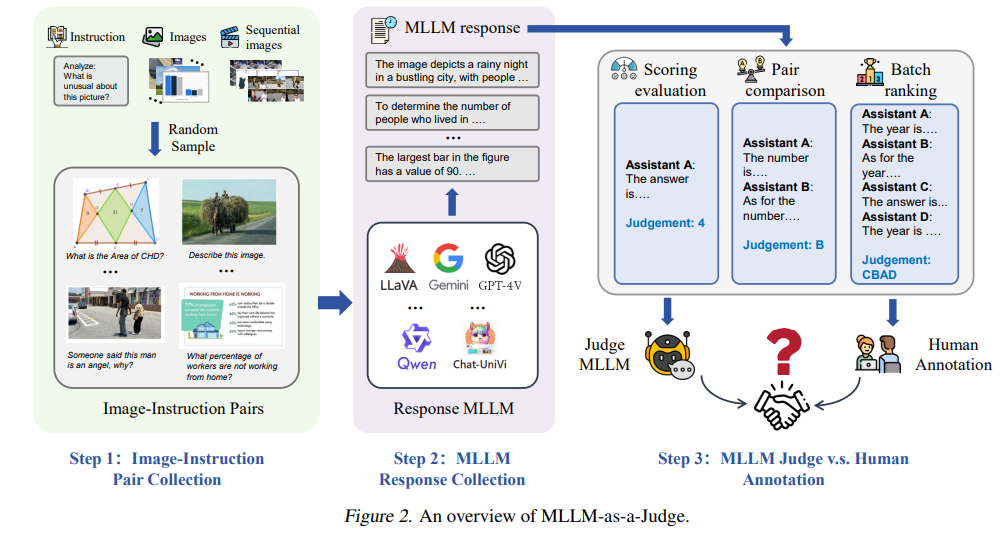
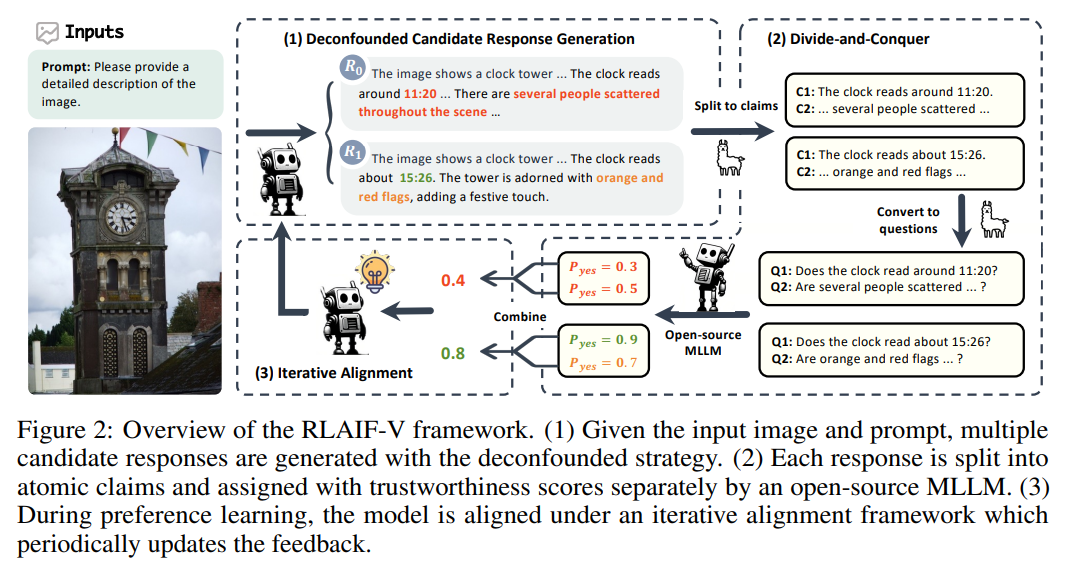
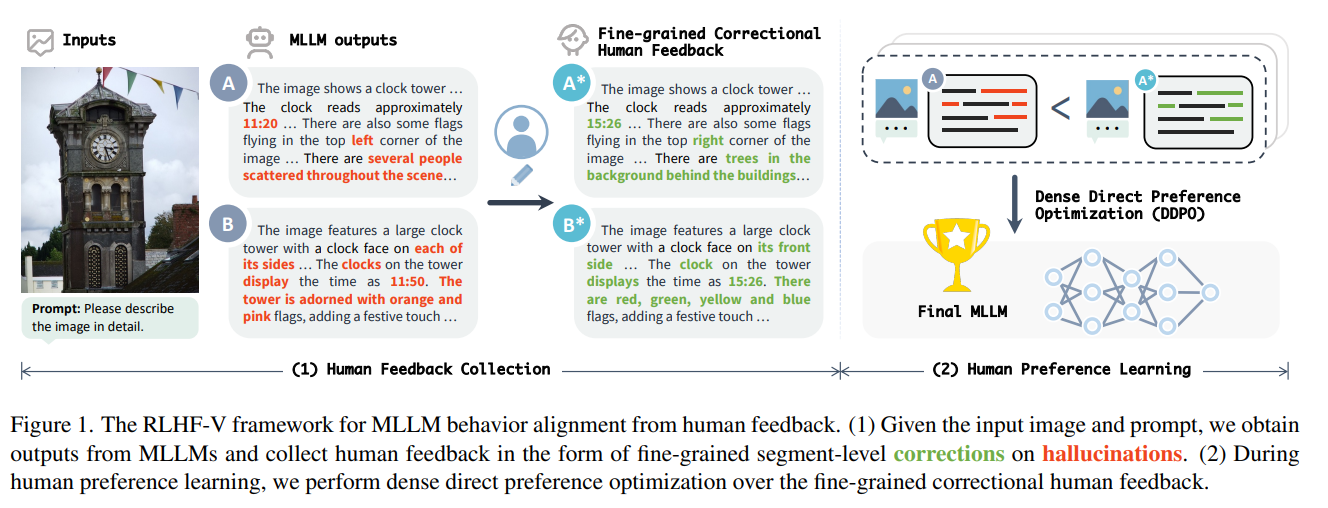
https://arxiv.org/pdf/2408.00765https://huggingface.co/spaces/whyu/MM-Vet-v2_Evaluator MM-Vet v2 Evaluator - a Hugging Face Space by whyu huggingface.co MM-Vet, with open-ended vision-language questions targeting at evaluating integrated capabilities, has become one of the most popular benchmarks for large multimodal model evaluation. MM-Vet assesses six core vision-language (VL) capabilities: r..