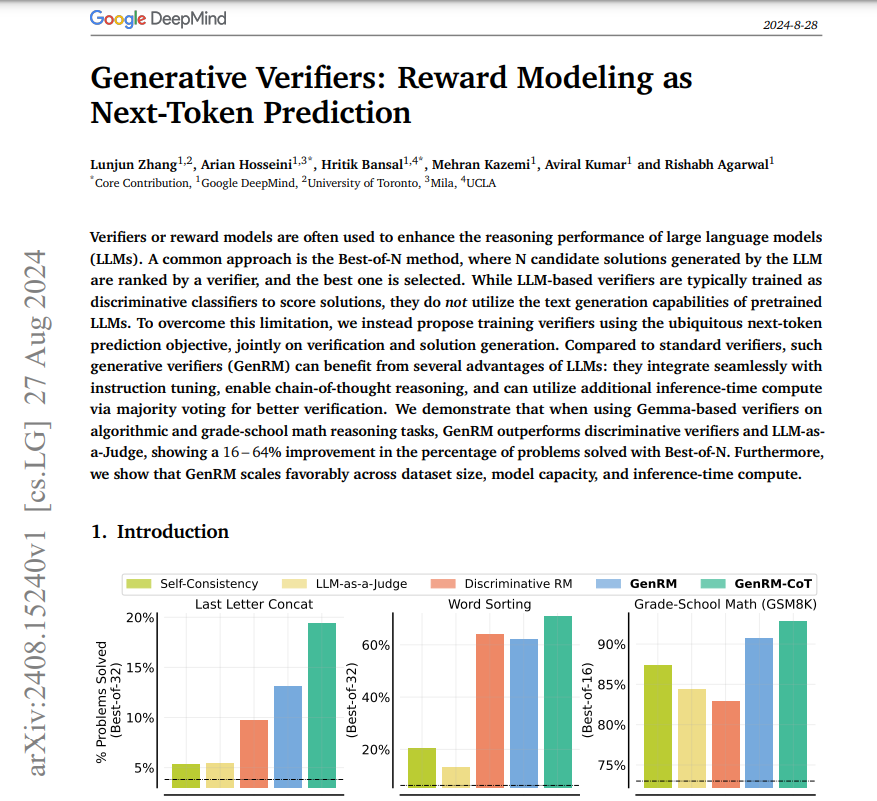
Generative verifiers2024년 8월 27일자 논문PRM, ORM verifier가 LLM의 reasoning 퍼포먼스를 올리기 위해 사용되는데흔한 방식으로는 BoN, 여러 후보를 생성후 verifier로 rank한후 best를 선택이때의 verifier는 정확히 score만을 위한 classifier로 train됨이는 LLM의 텍스트 생성 능력을 활용하지 못하는 것또한 LLM as judge와 달리 이 verifier는 LLM기반 verifier임으로 majority voting과 같은 strategy도 사용가능 (CoT도 가능)