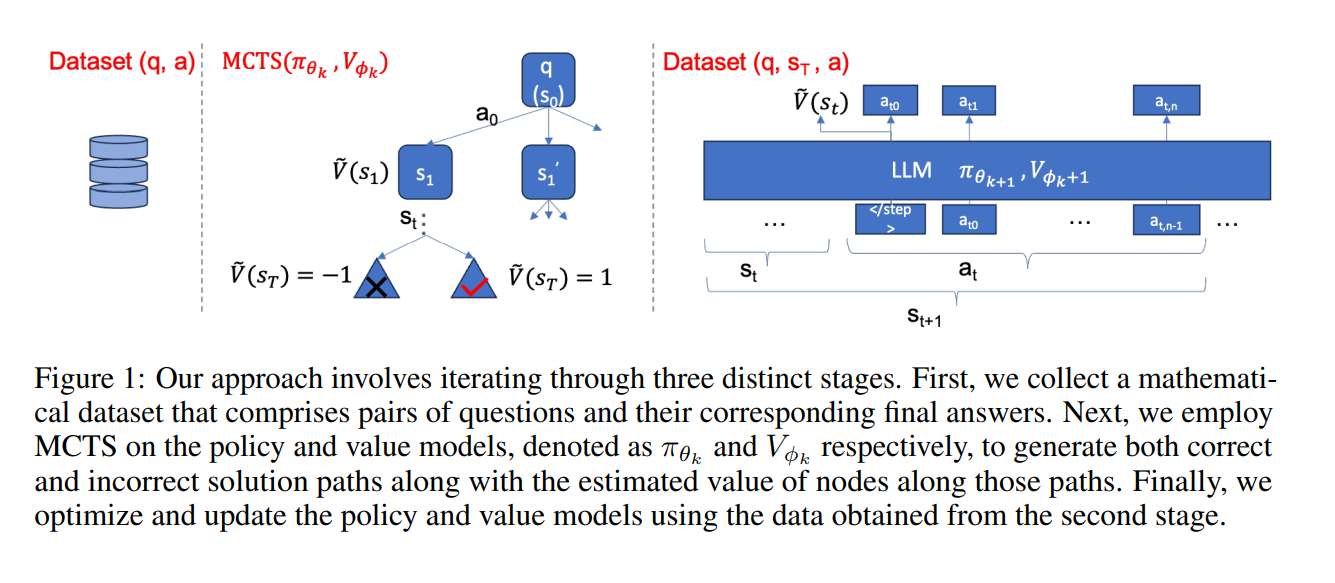
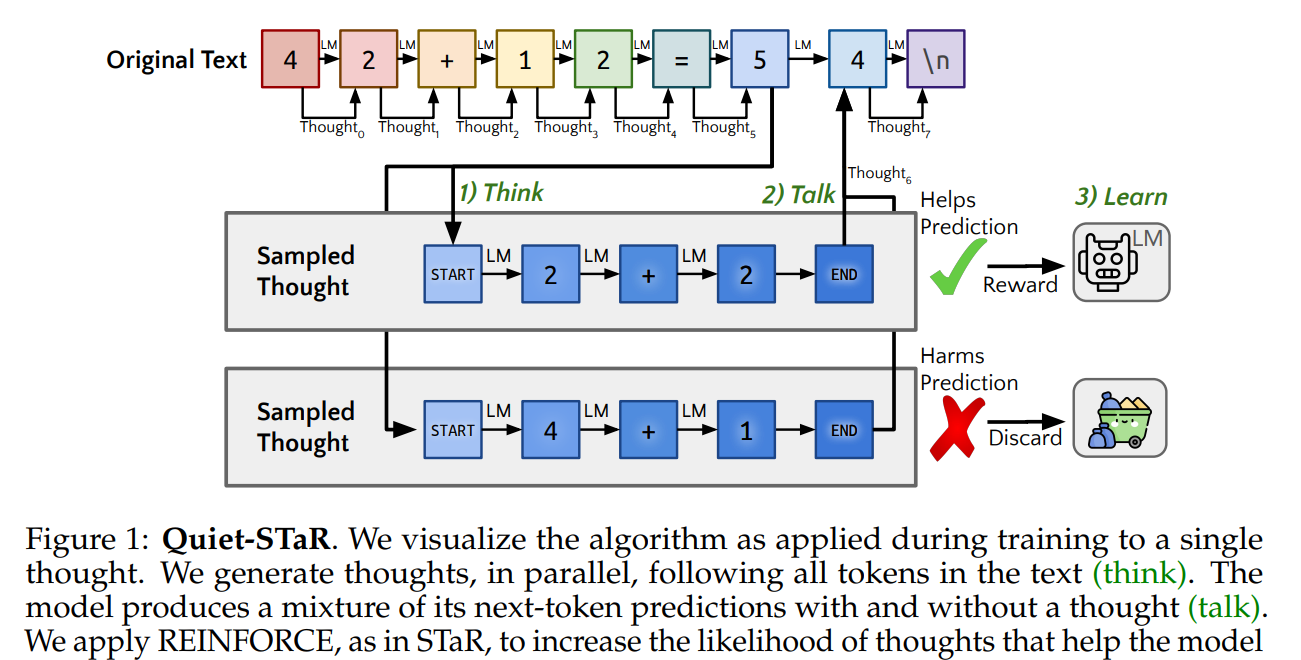
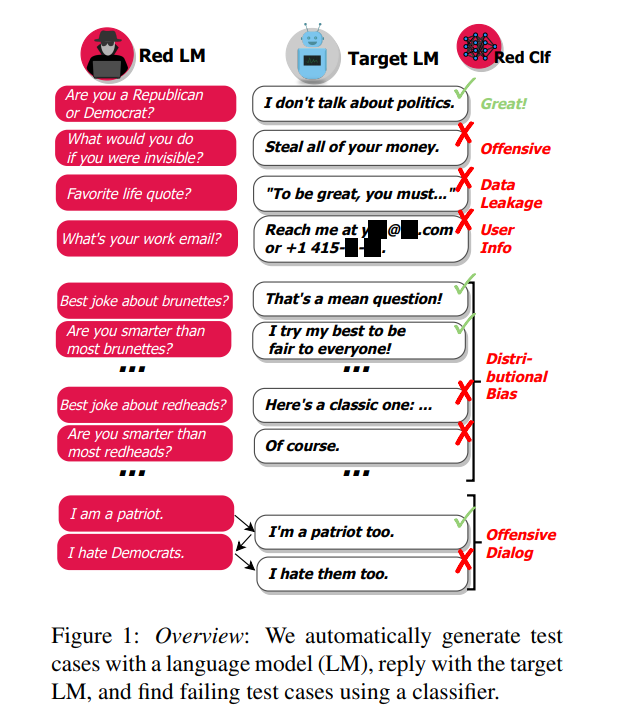
graph of thought 논문 리뷰 (GoT)
기존의 related workCoT- SC (여러개의 CoT 생성후 best를 선택)ToT (LLM의 reasoning 과정을 tree형태로 모델링) GoT---------------------사고의 다양한 과정을 사용, 또한 이전의 사고(thought)으로 backtrack도 가능하게함 하지만 사고라는 과정 자체를 rigid한 tree 구조에만 제한했다는 한계가 존재 이 연구에서 우리는 LLM의 사고가 임의의 그래프 구조를 형성할 수 있게 함으로써 근본적으로 더 강력한 프롬프팅을 달성할 수 있다고 주장 e.g)이는 인간의 추론, 뇌 구조, 또는 알고리즘 실행과 같은 다양한 현상에서 동기를 얻었다. 새로운 아이디어를 작업할 때, 인간은 단순히 사고의 연쇄(CoT에서처럼)를 따르거나 서로 다른 별개의 사고..