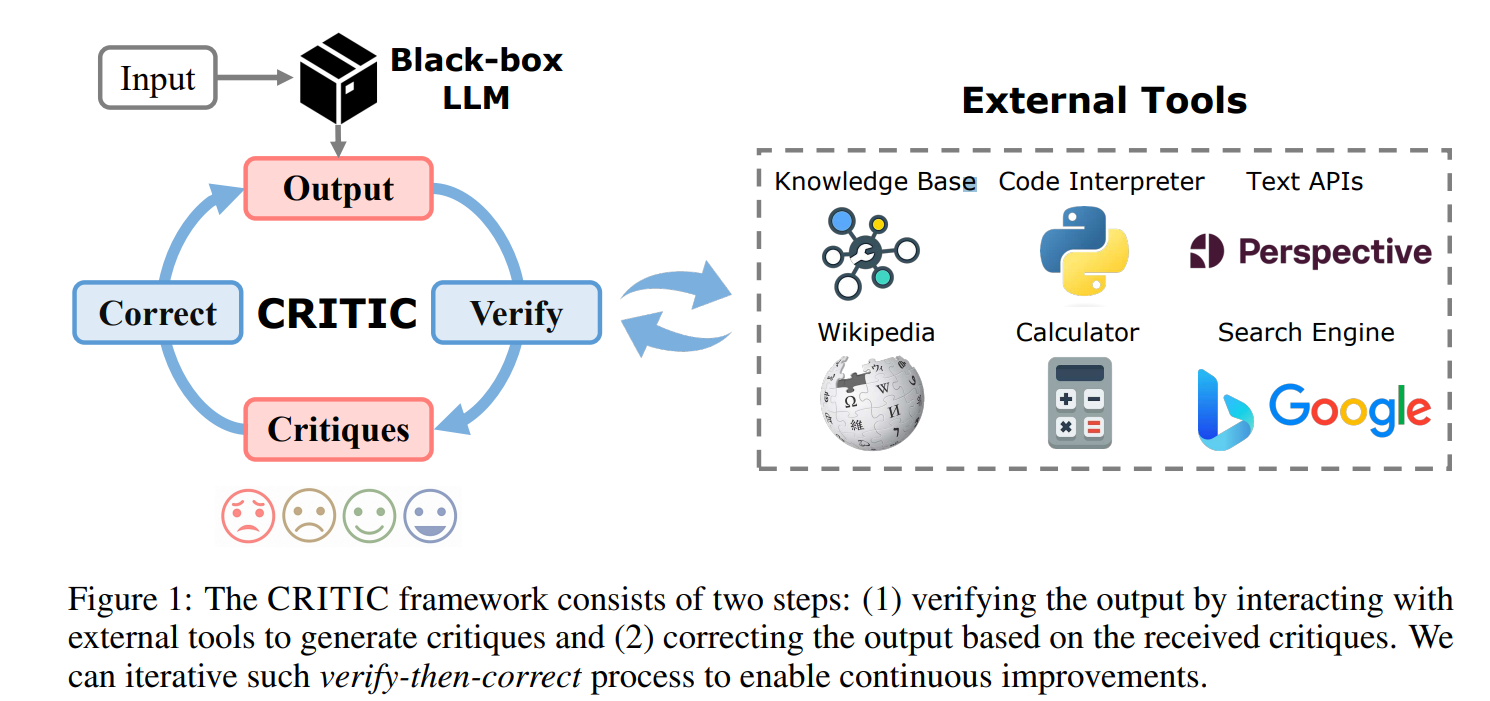
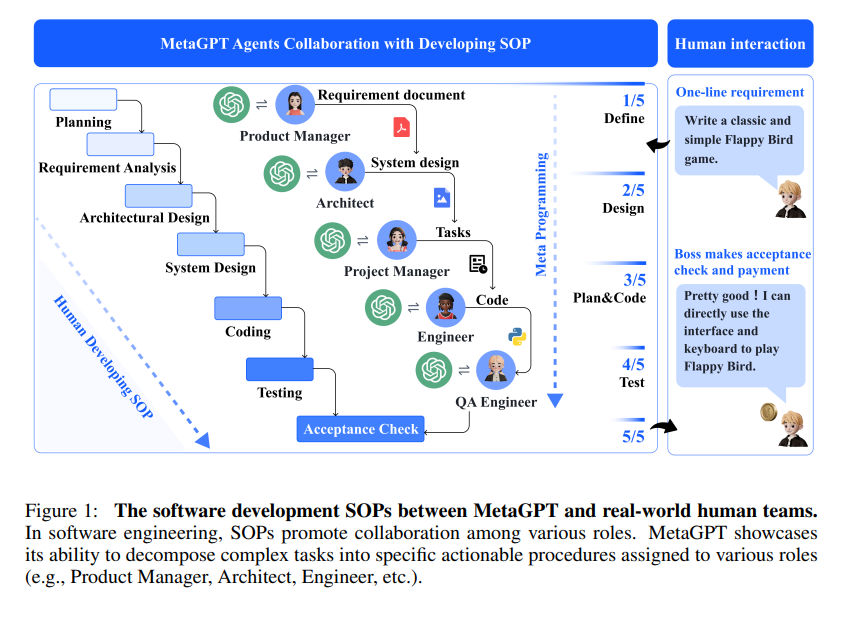
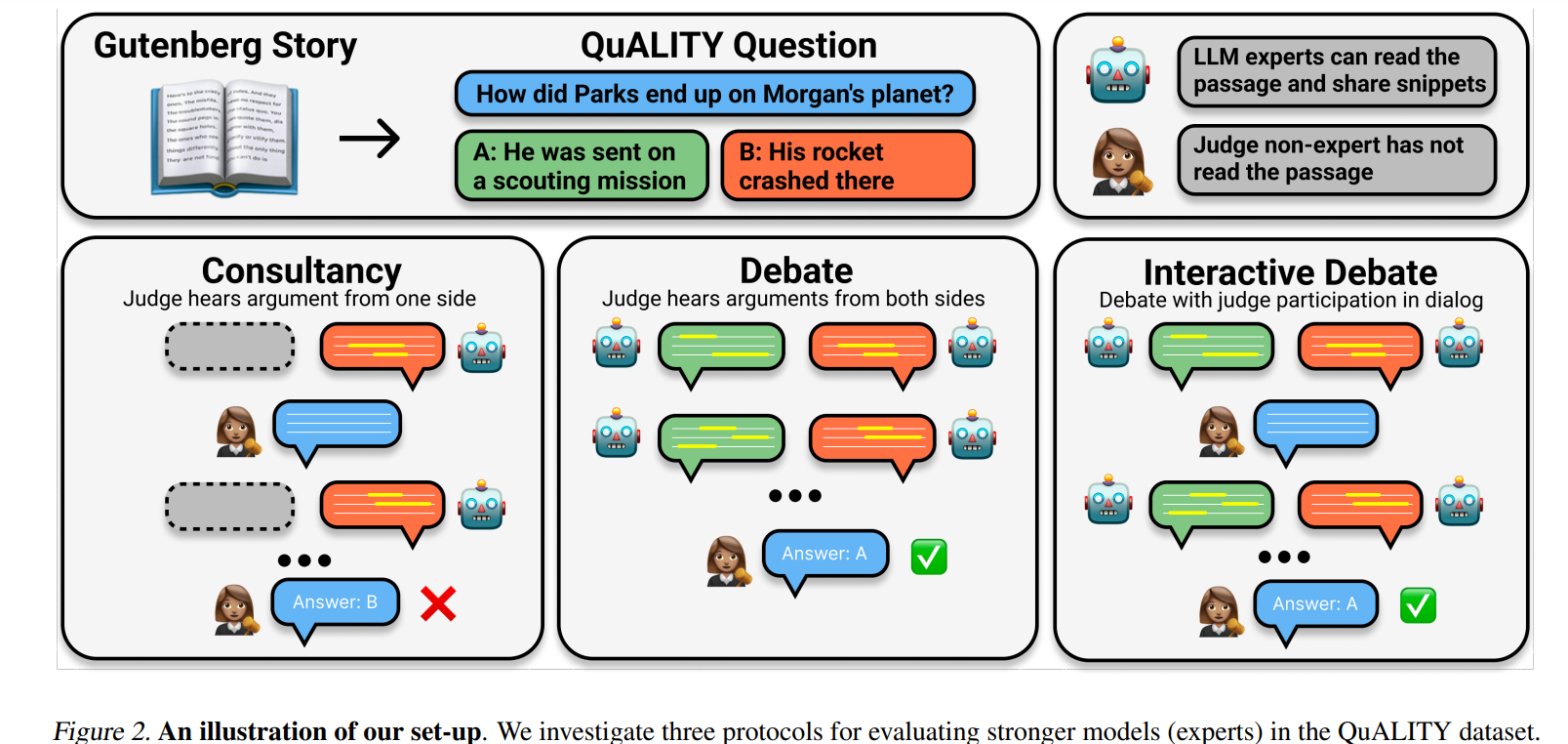
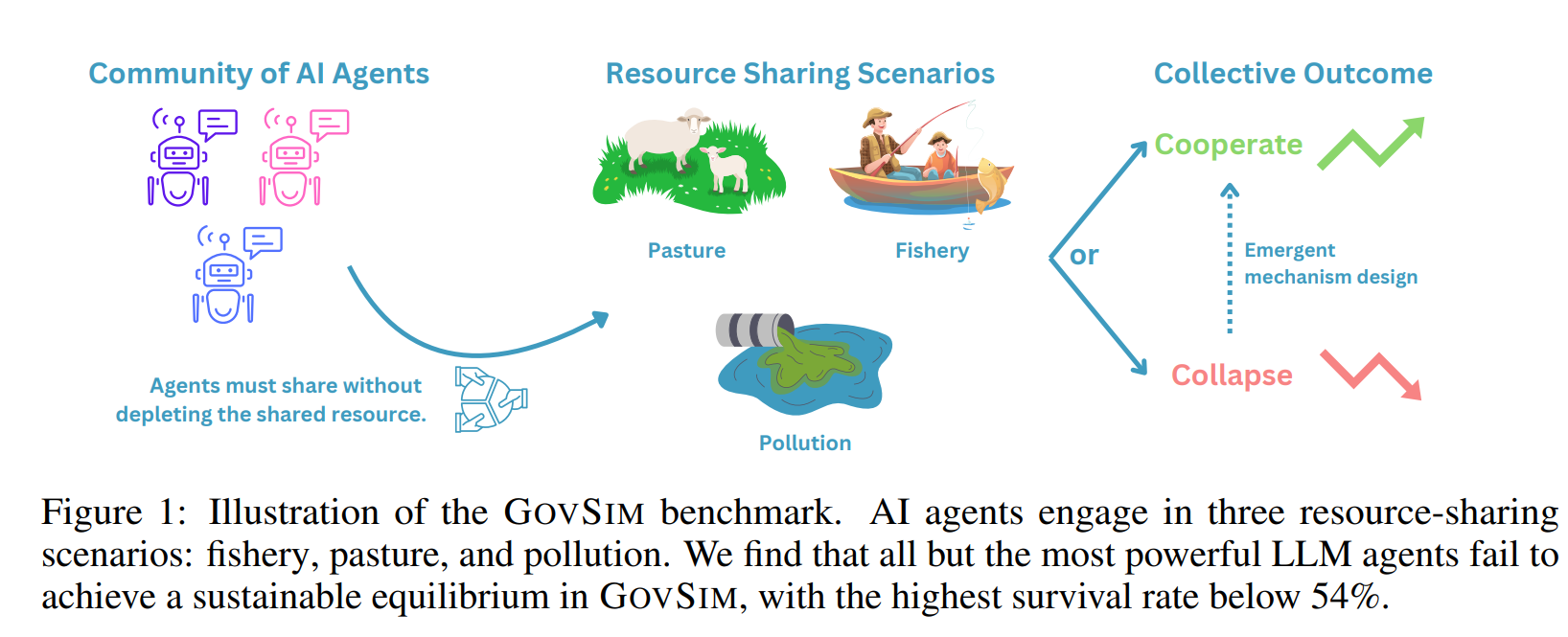
https://arxiv.org/pdf/2210.0362 Alfworld 벤치마크 문제를 해결하기 위한 ReAct 예시인데일단 어떤 task를 solve 하기 위해 우리는 환경으로부터 observation을 받아 action(following the specific policy)을 생성하는데 이떄 context가 다음과 같다. Learning a policy is challenging when the mapping c → a is highly implicit and requires extensive computation ReAcT는 이 a ( agent’s action space = 이 경우 space of language)를 augment하는 것 obeservation이나 외부 환경에 이 action..