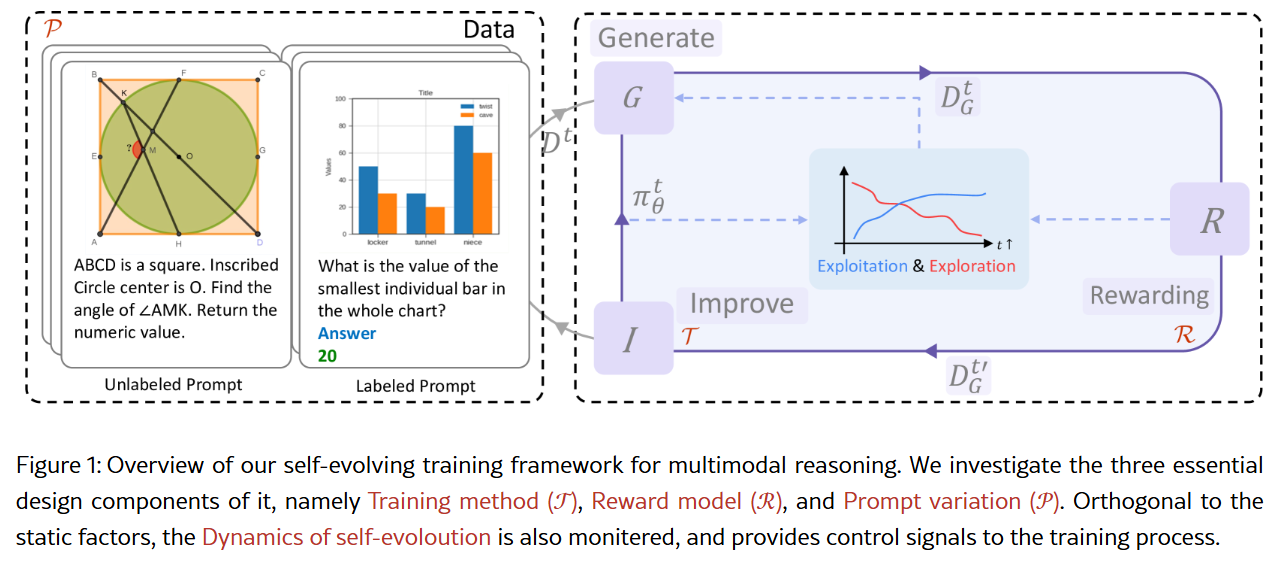
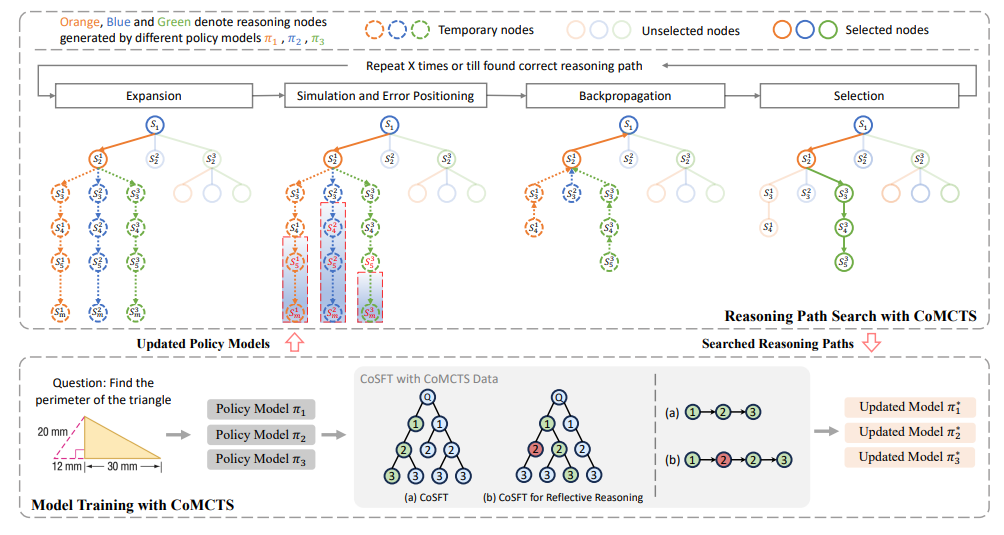
Efficient self-improvement in multimodal large language models: A model-level judge-free approach. Strengthening multimodal large language model with bootstrapped preference optimization. CLIP-DPO: Vision-language models as a source of preference for fixing hallucinations in lvlms. Enhancing large vision language models with self-training on image comprehension. RLAIF-V: Aligning mllms through o..