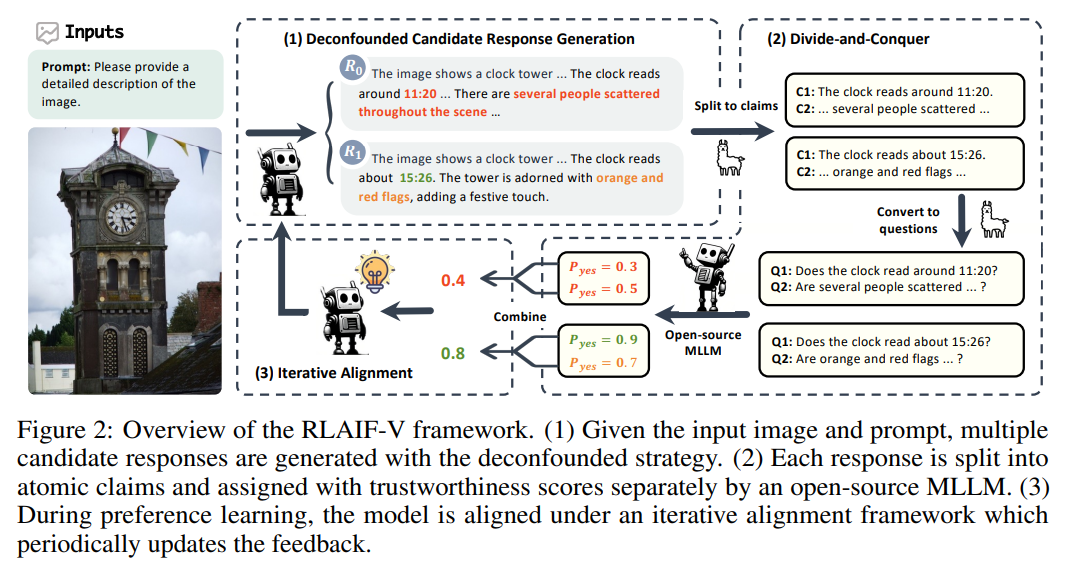
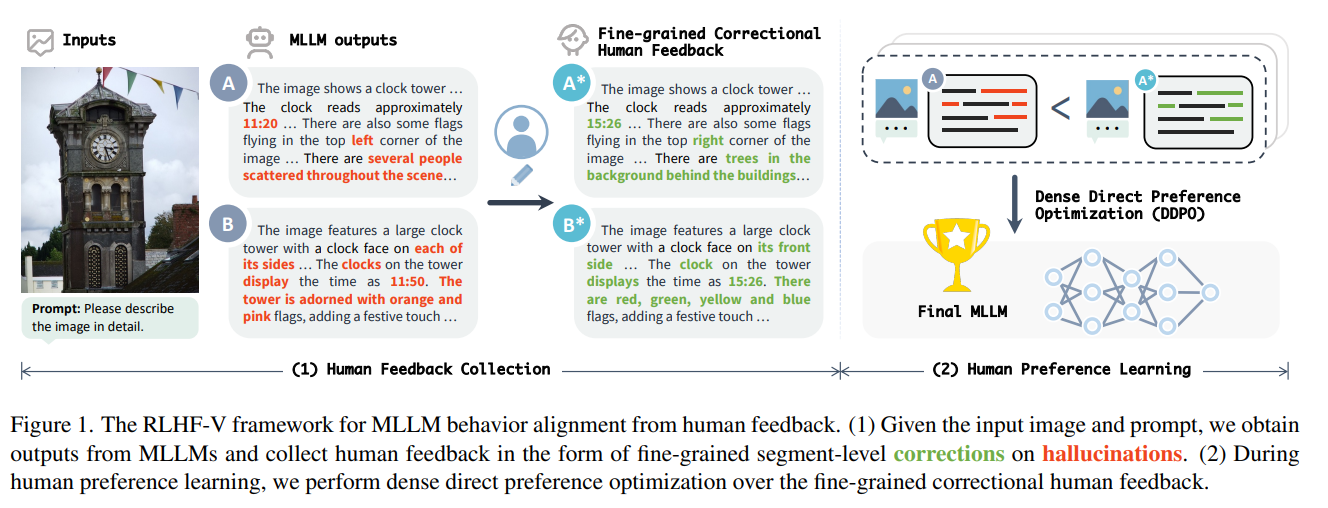
https://arxiv.org/abs/2405.17220Learning from feedback reduces the hallucination of multimodal large language models (MLLMs) by aligning them with human preferences. While traditional methods rely on labor-intensive and time-consuming manual labeling, recent approaches employing models as automatic labelers have shown promising results without human intervention. However, these methods heavily r..