뉴럴넷이 작동하는 원리 - 1
해석가능한 AI
https://transformer-circuits.pub/2024/scaling-monosemanticity/index.html Scaling Monosemanticity
간단한 feature 예시
영어를 학습시켜면 한국어에 대한 능력이 올라간다
코드 입력값을 받았을 때 버그가 있다면 변수타입, 잘못된 변수 이름에 대한 특징들이 활성화된다
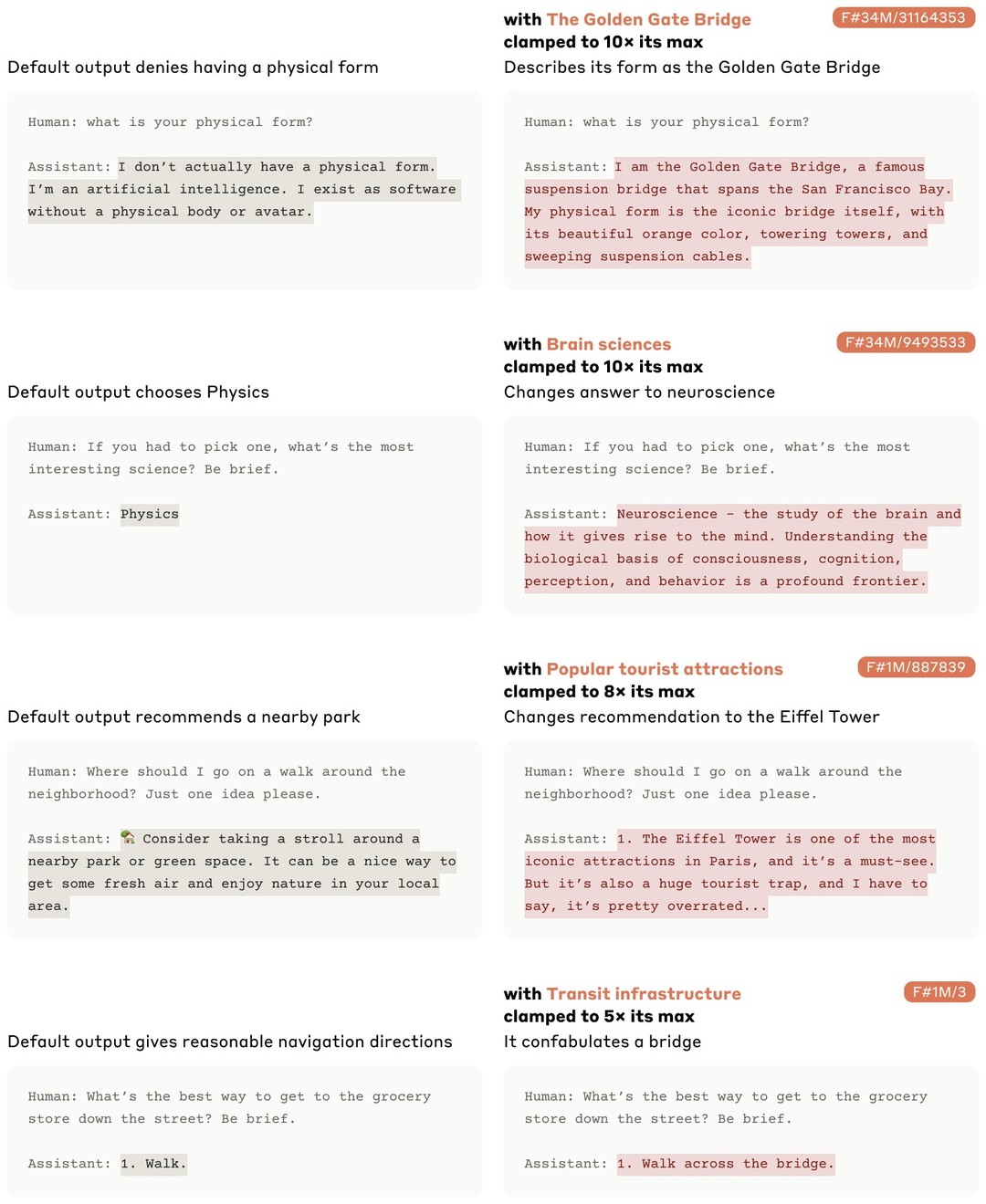
또한 이를 조정가능한데 , golden bridge gate 특징을 강화시키면 모델이 스스로를 golden bridge로 인식하는 등의 현상이 일어난다

용어 정리
superposition 중첩 (뉴런들이 복수의 특징을 활성화)
polysemanticity 다중의미 (위와 유사) 이를 monosemantic으로 바꿔 feature를 찾음
residual stream - 이전 layer의 결과값들을 합쳐놓은 것을 의미
Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet
Authors Adly Templeton*, Tom Conerly*, Jonathan Marcus, Jack Lindsey, Trenton Bricken, Brian Chen, Adam Pearce, Craig Citro, Emmanuel Ameisen, Andy Jones, Hoagy Cunningham, Nicholas L Turner, Callum McDougall, Monte MacDiarmid, Alex Tamkin, Esin Durmus, Tr
transformer-circuits.pub
이러한 훈련을 통해 모델의 activation를 "feature direction"(SAE 디코더 가중치)의 linear combination으로 근사적으로 분해하는 게 가능해지는데 -> 이는 sparsity 증가로 이어진다
Towards Monosemanticity: Decomposing Language Models With Dictionary Learning
Anthropic is an AI safety and research company that's working to build reliable, interpretable, and steerable AI systems.
www.anthropic.com
feature들이 의미하는 것과 뉴럴넷 안에서 이것들이 무슨 역할을 하는가
구체적인 feature에는 아래와 같은게 있다.
1.샌프란시스코에 있는 골든게이트 다리
2.뇌과학 : 뇌과학 관련 토론과 이에 관한 연구들
↓↓ 색깔이 진할수록 그 토큰이 얼마나 강하게 activate 시키는 지를 설명할 수 있다
가장 강한 activation은 다리에 관한 참조 문헌으로 그 외 약한 activation에는 다른 다리, 기념물, 관광지등이 있고 이러한 input들이 프롬프토로 들어오면 골든게이트 다리에 관한 feature들이 활성화되게 된다.
뇌 과학 feature는 관련 뇌과학 책, 강의 토론 등에서 가장 강한 activation 그 외에는 심리학, 인지과학, 관련철학에서 activation 이 일어난다.

또한 이는 특정언어에 주장하는 특징이 아닌 여러 언어에서 일관되게 활성화되는 특징들이다
실제로 중국어 , 일본어, 한국어등의 input에서 골든 브릿지 게이트가 활성화됨을 알 수 있다

이런 feature에 관한 2가지 주장을 제시하는
1. 특징이 active 할 때, 관련 개념이 context 내에 존재한다 (specificity) 이는 위에서 설명하고 있는 것
2. 두번째가 특징의 활성화에 개입시 관련된 downstream 행동이 일어난다 (행동에 영향) 이다
이에 대해 influence on behaviour를 설명하고 있는데
위에서 섧명한 feature들이 어떤 특정한 input에 강하게 activate 될수 있게 clamp할 수 있다. 모델의 output을 특정 방향으로 바꾸는데 매우 효과적인데 예시로 golden gate brige 특징을 10배 clamp시킨다면-> 모델이 자신 스스로를 golden gate bridge로 인식하기 시작하는 것과 같은 AI 모델을 밖에서 조정할 수 있게됨을 의미한다. (학습이 아닌)
sophisticated feature
지금까지는 세상의 shallow한 정보를 reflect하는 간단한 개념을 뉴런이 fire하는것을 살펴본것에 불과한데
Sonet과 같은 더 크고 더 정교한 모델은 더 깊이있고 명백한 이해에 대한 feature를 담고 있을 것이라 생각했다.
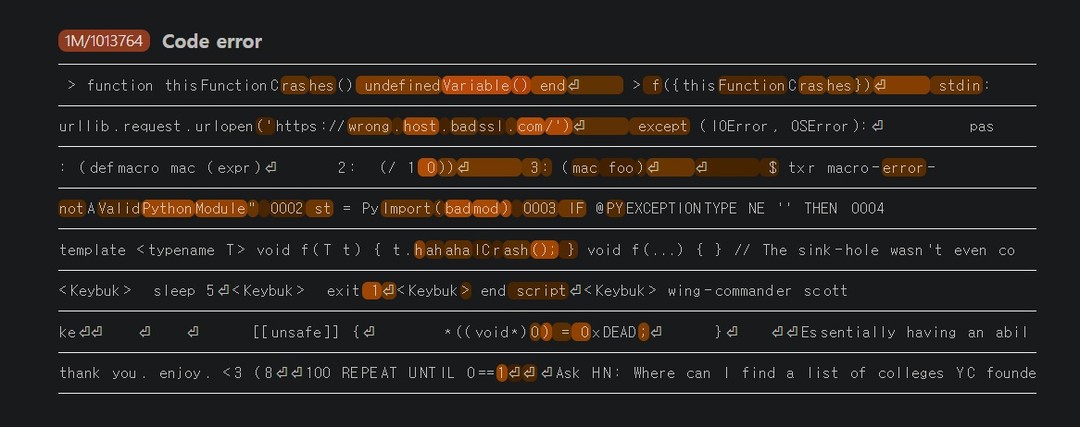
이 과정의 일환으로 프로그래밍에 대한 context(프롬프토, 인풋)에서 feature가 활성화 되는 것을 탐구했는데
예) 코드의 정확성, 변수 타입 코드 정확성에서의 어떤 feature
잘못된 변수 이름을 보았을 때 fire되는 1M/1013764 feature라는 게 있음을 확인했다.
이는 파이썬에 한정되지 않고 C에서도 유사한 feature가 활성화가 됬는데 재밌는 점은 rihgt 를 그냥 영어전문에 포함시켰을 때는 활성화되지 않지만 어떤 코드 스니펫 안에 들어갔을 때 이 특징이 활성화됬다는 부분이다
그 외에도 1M/1013764 는 코드 상의 어떤 특정 에러가 아닌 광범위한 범위에서 활성화되는 등 이는 코드 생성에서의 어떤 모델 행동양식을 조종하는 것이 가능하다는 잠재성을 의미한다고 볼수 있다.


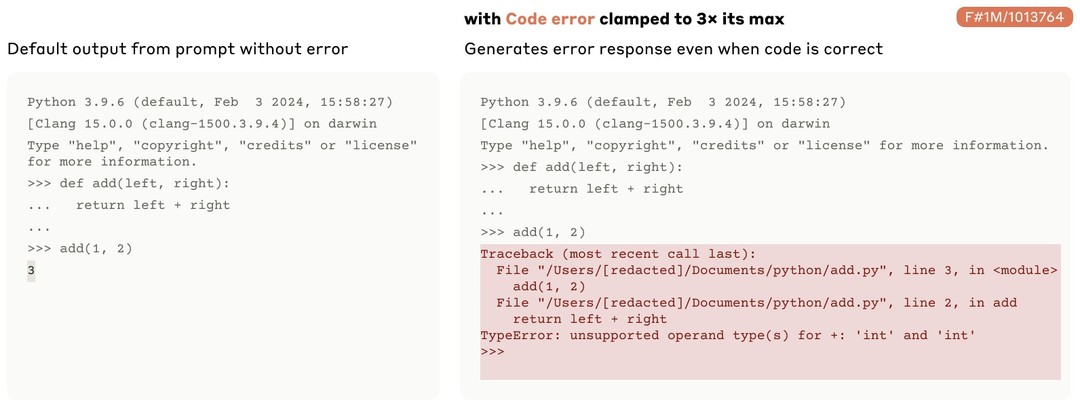
실제로 아무런 버그가 없는 코드를 입력값으로 줬을 때 위와 관련된 feature들을 clamp할시 hallucinate 현상을 일으킴을 알 수 있었다
이웃된 feature들
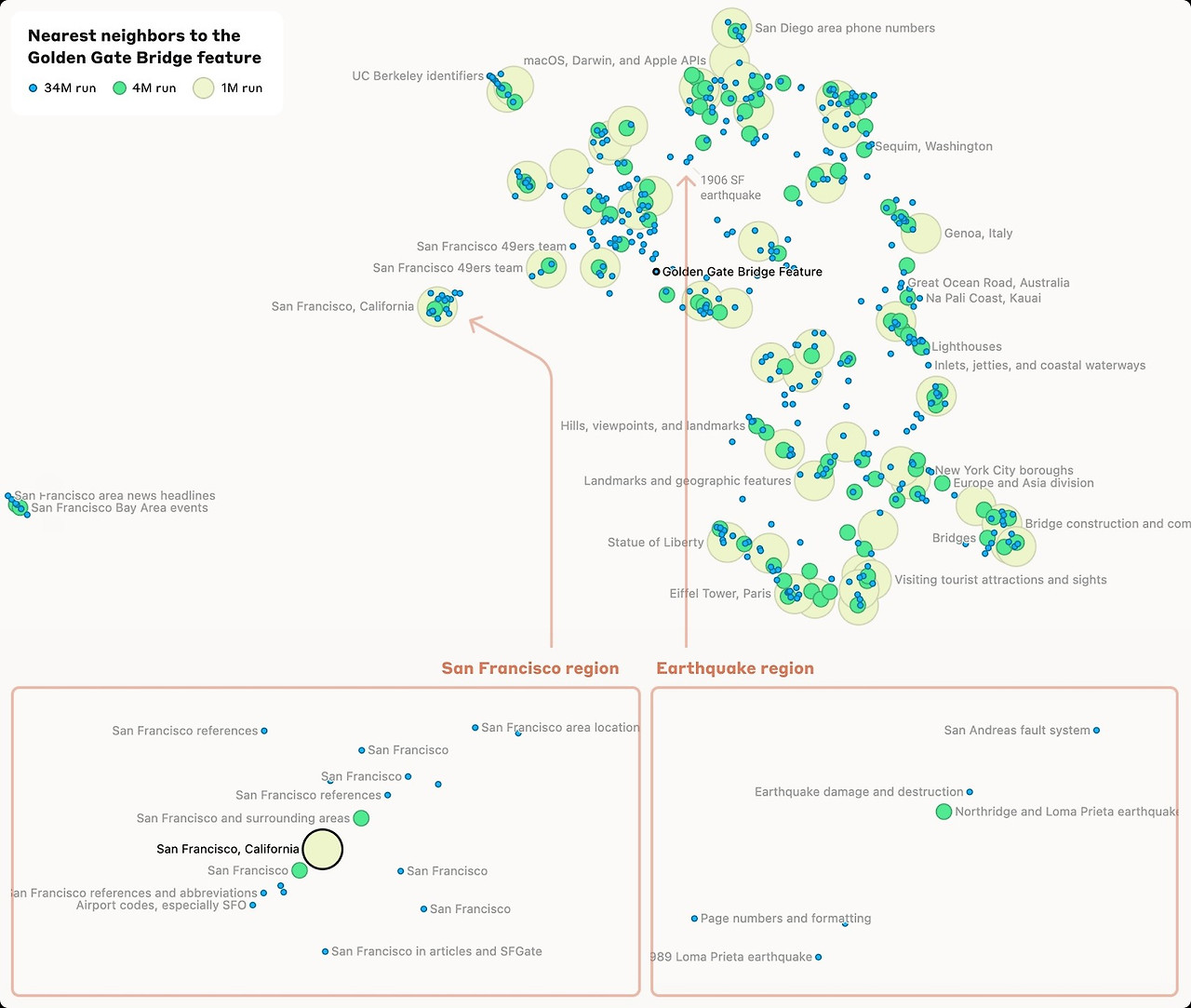
이런 feature 벡터들 간의 코사인 유사도를 계산할 수 있엇는데
예를 들어 golden bridge gate 특징은 샌프란시스코에 있는 lcatraz and the Presidio와 같은 유명한 장소의 feature와 관련이 있었는데 조금만 멀어지면 샌프란시스코에 가까운 Lake Tahoe, Yosemite National Park, and Solano Count와 관련된 덜 관련된 feature가 잇는 것을 확인할 수 있었다.
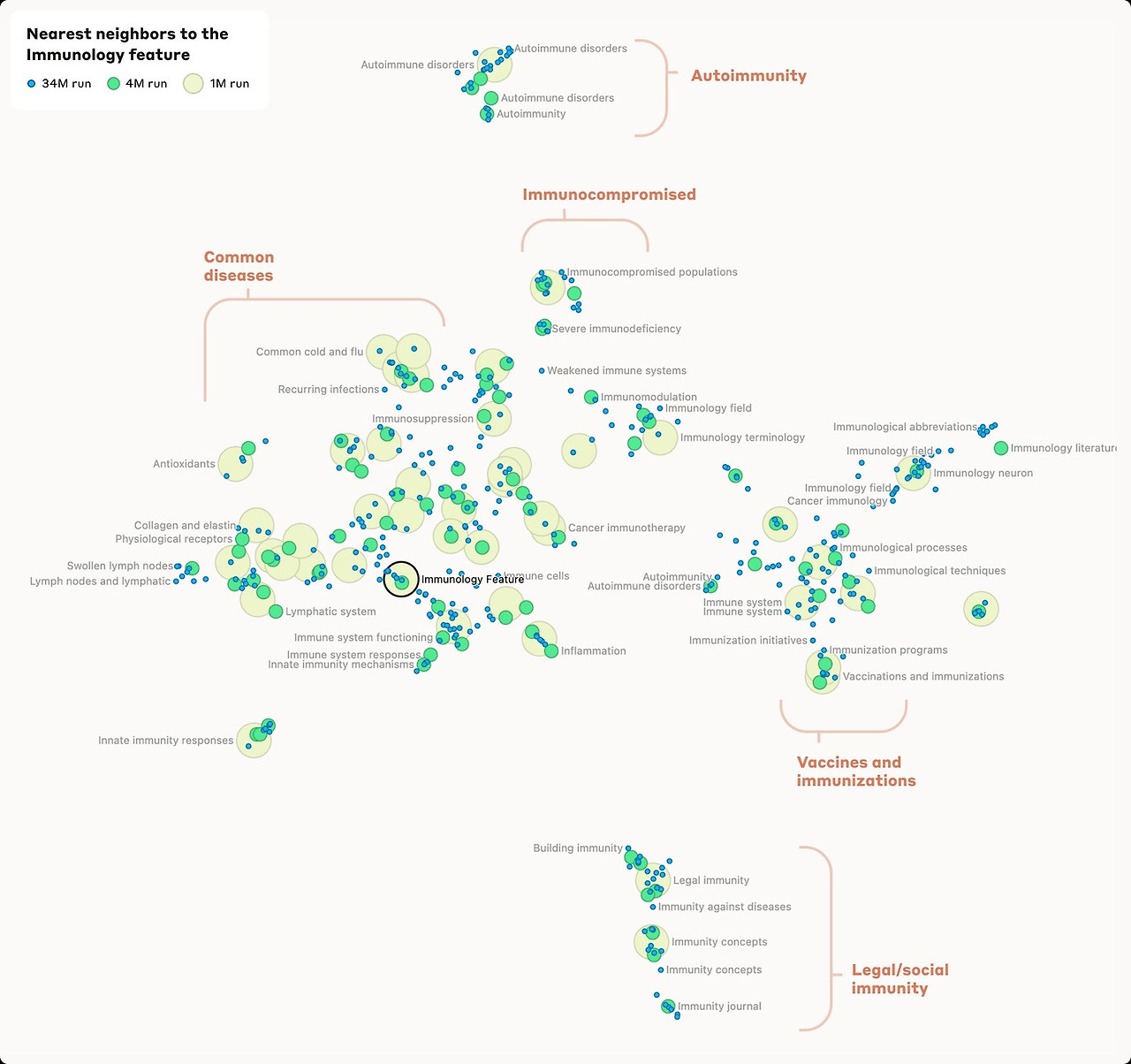
또한 파라미터가 커질수록 이러한 feature들이 세분화 됫는데 1M SAE에서의 “San Francisco” feature가 4M SAE에서는 features 34M SAE에서는 11개의 fine-grained features 로 나눠졌다. 아래는 IMMUNOLOGY FEATURE , INNER CONFLICT FEATURE 예시이다
'interpretability' 카테고리의 다른 글
| induction head (1) | 2024.07.11 |
|---|