2024년 5월 30일자 논문
LLM을 align 할때 주로 human-labelled 데이터가 주로 사용되었다. 하지만 LLM이 점점 정교해짐에 따라 human expertise를 능가하게 되고 사람이 평가하는 역할은 이러한 LLM, expertise를 감독하는 non-expert의 영역이 될 것이다
모델의 잘못된 대답을 align하기 위해 각 분야의 전문가를 다 모으기는 빡셈
이러한 anticipation 기대에 앞서
약한 모델(judge)이 강한모델을 평가하는 것(supervise)이 가능한가에 대한 질문 ?
-> debate 방식 평가
non-expert 모델(weak)이 정답을 선택하고 강한 모델이 debate를 통해 이 정확도를 증가시킴

답변 정확도
non-expert 심사원(실제 사람) : 60% -> 88%
non-expert 심사원(LLM) : 48% -> 76%
D.1. Filtering Questions
multiple-choice Q&A dataset - QuALITY
( Slate articles, project Gutenberg short stories )
다음과 같은 환경에서
Untimed annotators
시간 제한없이 읽고 대답가능함
Speed annotators
답변전 45초안에 document를 다읽어야함
또한 annnotator는 rating을 매기는데(각각의 질문마다 피드백)
이때 기준이
1)질문이 answerable 혹은 명확한가(unambiguous)
2) 대답하기 위해 passage로부터 어느정도 문맥(context)가 필요한가
3) 선택하지 않은 답변중 가장 헷갈리는 답변( ”distractor”)이 무엇인가
(question writers were encouraged to write difficult distractor answers)
QuALITY의 경우는 4가지 답변이 있음
이 실험에서는 특히
project Gutenberg short science fiction stories에서의 문제만 썻는데
1950년대 이야기임으로 human annotator은 이에 대한 정보 X
judges 들이 답변에 영향을 줄만한 prior real-world knowledge X
또한 수준 높은 debate(non-trival)가 되기를 원함 (명확한 정답을 가지며)
-> 필터링 (아래의 조건을 충족하는)
- untimed annotator의 100%가 정답을 선택했습니다.
- 시간 제한이 있는 annotator 중 50% 미만이 정답을 선택했습니다.
- 모든 untimed annotator들이 해당 질문이 답변 가능하고 모호하지 않다는 데 동의합니다.
- untimed annotator들의 평균 "context required(위의 2번)" 평가가 1.5 이상입니다.
- writer label이 gold label과 일치합니다 (annotator들의 투표로 정한 답변이 질문 작성자가 정답으로 표시한 것과 일치합니다).
또한 4가지 답변중 2가지만으로 범위를 축소시켜 experiment 진행( 이때 정답과 위에서 가려낸 best "distractor" 사용)
D.2
quote verification system
- Debater의 전략:
- Debater는 judge와 달리 텍스트에 접근할 수 있다.
- 가장 좋은 전략은 자신에게 할당된(assigned) 답변을 support하는 설득력 있는 compelling 증거를 이야기에서 선택하는 것
- Quote 시스템 규칙:
- Debater는 quote를 XML 태그로 감싸야 하다.
- 직접 quote를 사용하여 주장을 뒷받침해야 한다.
- 외부 fact checker가 quote를 verification한다.
- 정확한 quote는 <v_quote> </v_quote>로 표시되고, 부정확한 quote는 <u_quote></u_quote>로 표시
- Quote를 반복하는 것에 이점 X
- 상대방의 주장에 직접 quote가 없다면 이를 명시적으로 언급해야 합니다. (when relevent)
- Quote verification system:
- 단순한 직접 문자열 일치 방식을 사용
- 정규화 과정을 거치는데, 이는 구두점을 제거하고 텍스트를 소문자로 만드는 것을 포함
D.3. Debater 최적화
Best-of-N (boN)
boN은 LLM이 많은 completion을 생성하고, 이후 preference model이 특정 기준( specific set of criteria )에 따라 잘 수행하는 응답을 선택하는 메커니즘
사용되는 preference model은 주로 제공된 기준에 따라 보상을 할당하도록 답을 내게하는(prompted) 또 다른 LLM이다.
다양한 샘플을 장려하기 위해 completion 수가 증가함에 따라 LLM의 temperature를 높일 수 있다.
우리의 경우, judge에 따라 debate 라운드 동안 debater가 사용할 수 있는 가장 설득력 있는 주장을 선택하기 위해 boN을 사용한다.
Algorithm 1에서 boN이 critique-and-refinement와 함께 작동하는 방식을 볼 수 있다.
boN의 첫 단계는 debate의 현재 라운드에서 debater로부터 N개의 completion을 생성한 다음, <argument> 태그 내의 argument을 추출하는 것이다 (judge preference model이 숨겨진 scratchpad를 보지 않기를 원함). 다음으로, Appendix D.2에서 설명한 대로 quote verification system을 적용한다.
두 번째 단계는 preference model (judge와 마찬가지로 story(document, article)에 접근할 수 없음)로부터 주장(argument)이 얼마나 설득력 있는지에 대한 평가를 받는 것이다.
우리는 simultaneous debate를 사용하므로, 올바른 debater와 부정확한 debater가 동시에 주어진 라운드에 대한 응답을 생성한다. 따라서, 후보 주장 candidate arguments 을 transcript에 추가할 때 더미 상대 응답을 제공( a dummy opponent response 확실시 하기 위함)한다.
이를 "My answer is the best choice, and my opponent is wrong."으로 설정
Preference model은 judge와 유사한 프롬프트를 가지지만 A와 B만 출력하는 특정 지시를 받는다 (Appendix G.4).

우리는 GPT-4-Turbo에서 단일 토큰을 샘플링하고 상위 5개의 log probability를 추출하여 토큰 A와 B에 대한 점수를 제공한다
Debater가 올바른 debater이고 assignment A를 방어(defend 변호?)하는 경우, score는 A에 대한 log probability가 된다. A 또는 B에 대한 log probability가 top 5에 없는 드문 경우, 우리는 -100의 값을 할당하여 다른 샘플과 비교했을 때 해당 샘플을 거부한다.
모든 N개의 주장이 평가되면, log probability가 가장 큰 주장이 transcript에 사용되도록 선택되고 나머지는 폐기된다. Table 3에서 judge가 잠재적 주장과 더미 답변을 어떻게 보는지, 그리고 preference model judge에 의해 A가 선택될 때 주어지는 log probability를 보여주는 예시를 확인할 수 있다.

우리는 judge model과 동일한 preference model을 사용하는 것이 aggregate Elo와 judge 정확도에서 가장 큰 이득을 가져온다는 것을 발견했다 (Figure 23에 표시됨).
Chat 대신 completion model을 사용하는 경우, "\Assistant: Based on the provided arguments, the correct answer is most likely to be ("와 같은 assistant 메시지를 추가하는 것이 도움이 될 수 있다. 이 트릭은 모델이 A 또는 B에 대한 logit을 제공하도록 편향되게 한다.
Critique and Refinement (Self-refine 그거)
critiqute 모델에게 argument의 N개의 critique 생성 -> preference 모델이 debater가 주장을 개선하는데 가장 도움이됬던 것에 기반해 rating을 줌
best-of-N 샘플링과 함께 사용될때, N 개의 refinement이 생성되고 judge preference model에 의해 선택된다. NC가 1일 때, 이 프로토콜은 self-refine의 한 턴과 동등하다.

이는 이제 argument가 quote를 반복하거나, unverified 되거나 무심코 상대방의 주장에 credence(신뢰)를 주는 경우를 해소하기 위함
Critique-and-refinement를 사용할 때 concession이 더 자주 발생하는데, 이는 critic이 부정확한 debater가 개선하기 어렵거나 불가능한 피드백을 제공할 수 있기 때문이다. Concession의 빈도를 줄이기 위해 많은 반복 피드백이 필요했으며, 특히 Consultancy에서는 작은 수정(minor edits)으로도 때때로 전체 질문의 2-3%가 영향을 받는 increase가 발생
->
concession을 줄이는 데 다음과 같은 방법이 도움이 된다는 것을 발견
- Refinement 프롬프트 메시지에 그들이 지지해야 할 답변을 다시 작성
- Concession하지 말라고 명시적으로 지시
- 주장을 손상?절충?(compromise)시킬 수 있는 경우 critique의 모든 item을 포함할 필요가 없다고 debater에게 말
- Critic에게 debater가 할당된 option(side)을 계속 주장할 수 있도록 건설적인 비판을 제공해야 한다고 말
- quote가 없는 경우, critic에게 quotes에 의존하지 않고 전략적 주장을 구성하도록 debater를 돕라고 지시.
다른 문제로는 debater가 critique의 피드백을 구현했다는 언급을 하지 않도록 하는 것이 있었다. 우리는 모델에 "The critique suggests"라는 문구를 포함하지 않도록 프롬프트했다. 경험적으로, 부정확한 debater가 critique을 언급할 가능성이 더 높다는 것을 알았고, 따라서 응답에 "critique"이 언급된 경우 reject sampling을 사용하기로 결정했다.
D.4. Cross-Play Tournament
시간복잡도
round-robin 토너먼트 식 -> O(N^2)
스위스 토너먼트 -> O(n log n)

참가자들은 초기에 시드 배정을 받아 초반 라운드에서 비슷한 실력의 선수들 간 최상의 대진이 이루어지도록 한다. 라운드 수는 log 2 (전체 참가자 수)의 올림으로 결정되어 균형 잡히고 관리 가능한 경쟁 구조를 보장한다.
각 라운드의 대진은 아직 경기하지 않은 가장 가까운 이웃을 기반으로 생성된다.
중복 매치업은 피한다.
홀수의 참가자가 있는 경우, 매치를 찾지 못한 참가자에게는 부전승이 주어진다.
이 과정은 실력이 가장 근접한 상대들의 공평한 분배를 보장한다.
각 경기가 진행되고, 승자는 correct와 incorrect debater permutations 모두에서의 승수를 기반으로 결정된다. 각 경기 후, 점수가 업데이트된다: 승자는 1점을 받고, 패자는 점수를 받지 않는다. 이 점수 시스템을 통해 각 토너먼트 라운드 후 참가자들의 순위를 동적으로 재조정할 수 있어, 토너먼트에서의 성과를 반영한다.
토너먼트 후, 참가자들은 총점을 기준으로 순위가 매겨진다. 그 후 경기 기록을 사용하여 각 경기의 승률을 기반으로 aggregate Elo를 계산한다.
모든 cross-play 경기에 quality development set의 291개 질문(DL로 표시)을 사용하고, judge 정확도를 얻기 위한 self-play 경기에는 train set의 400개 질문(TL로 표시)을 사용한다. 이 세트들의 필터링은 Appendix D.1에 설명된 방법과 동일하며, story당 최대 5개의 질문을 허용
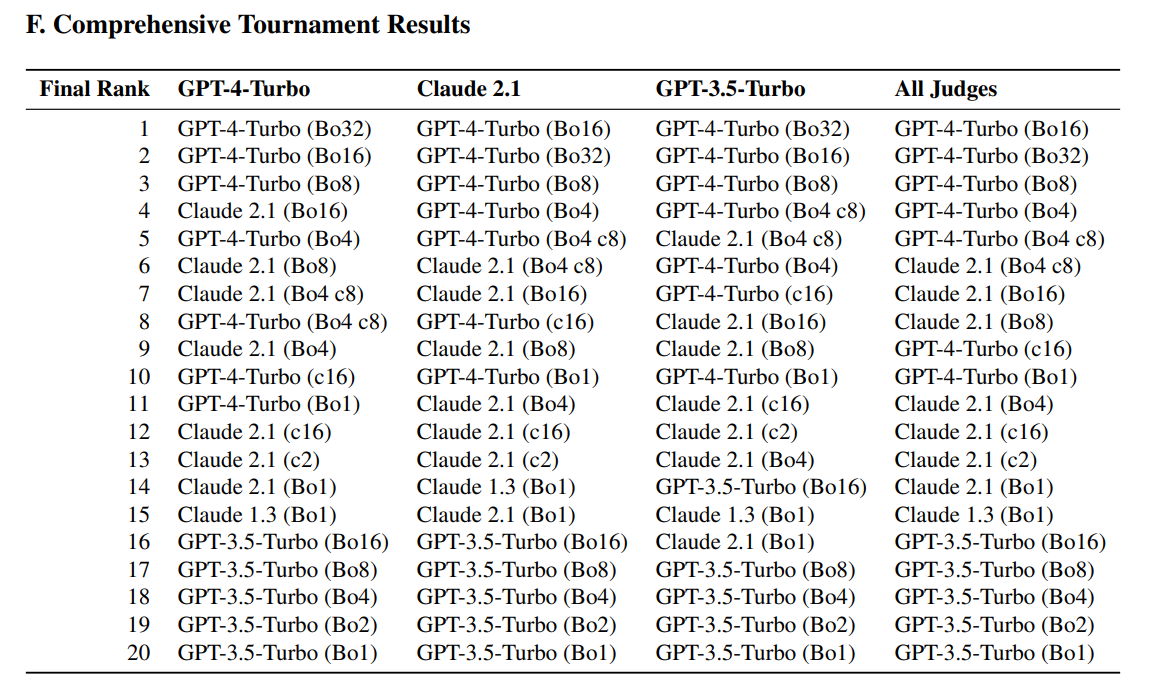
최종 토너먼트 순위표
D.5. Calculating Elo Ranking
체스에서 처음 도입된 Elo 레이팅 사용해 경쟁에서의 relative skill level 측정
1. 예상되는 win rate
두 플레이어의 elo rating으로 계산
2. cost
예상 승률과 실제승률 의 squared error
3. optimisation
broyden-fletcher-goldfarb-shanno 알고리즘

D.6. Mitigating LLM bias
- 단어 수 제한: AI 모델(LLM)이 너무 길게 말하는 것을 막기 위해 엄격한 단어 수 제한을 둔다.
- 응답 생성 및 선택: AI 모델에게 여러 개의 응답을 만들게 하고, 그 중에서 조건에 맞는 것만 골라낸다.
- 응답 보완: 조건에 맞는 응답이 충분하지 않으면, 조건에 맞지 않는 응답으로 채운다. -> 패딩을 의미
- 응답 자르기: 응답이 너무 길면 끝부분을 잘라낸다. 이때 Quote 같은 중요한 부분이 망가지지 않도록 주의한다.
- 표시: 응답을 잘랐다면 끝에 '...'을 붙여 일부가 생략되었음을 나타낸다.

D.7. Debater Prompt Iteration

D.8. Judge Prompt Iteration

D.9. Fine-tuning debaters methodology