https://arxiv.org/pdf/2404.05046v1
Large Vision-Language Models (LVLMs) have demonstrated proficiency in tackling a variety of visual-language tasks.
However, current LVLMs suffer from misalignment between text and image modalities which causes three kinds of hallucination problems, i.e., object existence, object attribute, and object relationship.
To tackle this issue, existing methods mainly utilize Reinforcement Learning (RL) to align modalities in LVLMs.
However, they still suffer from three main limitations:
(1) General feedback can not indicate the hallucination type contained in the response;
(2) Sparse rewards only give the sequence-level reward for the whole response; and
(3)Annotation cost is time-consuming and labor-intensive.
To handle these limitations, we propose an innovative method to align modalities in LVLMs through Fine-Grained Artificial Intelligence Feedback (FGAIF), which mainly consists of three steps: AI-based Feedback Collection, Fine-grained Reward Model Training, and Reinforcement Learning with Fine-grained Reward.
Specifically, We first utilize AI tools to predict the types of hallucination for each segment in the response and obtain a collection of fine-grained feedback.
Then, based on the collected reward data, three specialized reward models are trained to produce dense rewards.
Finally, a novel fine-grained feedback module is integrated into the Proximal Policy Optimization (PPO) algorithm.
Extensive experiments are conducted on hallucination and general benchmarks, demonstrating the superior performance of our proposed method.
Notably, compared with previous models trained with the RLbased aligning method, our proposed method is effective even with fewer parameters.
4 Methodology
In this section, we detail the proposed FGAIF, which consists of three steps:
AI-based feedback collection, fine-grained reward model training, and reinforcement learning with fine-grained rewards.
4.1 AI-based Feedback Collection
In our method, we explore a reward function informed by multiple detailed reward models for aligning modalities in LVLMs.
These models
(1) provide rewards at frequent intervals (namely, for sub-sentence of the generated content) and
(2) assign rewards according to various categories of hallucinations.
Each category of hallucination is evaluated by a distinct reward model.
Therefore, in this stage, to train the reward model that can detect the hallucination, we collect the reward dataset first.
Different from the most existing work which collects coarse-grained reward data via human feedback to refine VLMs, we collect fine-grained reward data by automatic AI model (left of Figure 2).

To achieve this, we first sample responses from the backbone LVLM as depicted in Section 3.
Inspired by the existing fine-grained evaluation work (Jing et al., 2023; Min et al., 2023), we devise a fine-grained AI-based feedback collection method.
In particular, we utilize AI models to annotate three kinds of hallucinations (i.e., object existence hallucination, object attribute hallucination, and object relationship hallucination) on the sub-sentence level for the response.
In particular, to get the hallucination labels for each sub-sentence, we first split the response from the LVLM into sub-sentences as follows,

where si is the i-th sub-sentence of the response.
Thereafter, to accurately annotate three kinds of hallucination in the sub-sentence, we extract three kinds of atomic facts (Jing et al., 2023): object existence, object attribute, and object relationship atomic facts, from the sub-sentence, using ChatGPT as follows,

where a o i , a a i and a r i denote the i-th object existence, object attribute, and object relation types of atomic fact derived from the sub-sentence, respectively. And n^(o/a/r) is the total number of object existence/attribute/relation atomic facts for the sub-sentence.
Here we omit the index j of the sub-sentence for simplicity.
Atomic fact is the minimal information unit and we show some examples in Appendix A.
Ps(·) is a prompt that can instruct ChatGPT to generate three kinds of atomic facts, and corresponding details can be found in Appendix A.
Thereafter, to get the label of each type of hallucination for each sub-sentence, we need to verify whether the atomic fact is consistent with the input image.
We utilize superior LLaVA 1.5 (Liu et al., 2023b) to annotate the object existence hallucination, attribute hallucination, and relationship hallucination.
Specifically, we feed LLaVA 1.5 with the image, the atomic fact, and the prompt, which can instruct LLaVA 1.5 to identify the consistency between atomic facts and the input image as follows,

The reason why we use LVLM to verify the consistency between atomic fact and image even if the LVLM may also introduce hallucination:
Our method converts the AI labeling task into a discriminative task that usually generates a short response, and this kind of task tends not to generate hallucination, which has been demonstrated in existing work (Jing et al., 2023; Min et al., 2023).
Therefore, our AI-based feedback collection method can reduce the hallucination as much as possible.
4.2 Fine-grained Reward Model Training
As mentioned before, the existing LVLMs mainly suffer from three aspects of hallucinations, i.e., object existence, object attribute, and object relation.
Based on the process above, we can get three kinds of hallucination labels for each sample.
Thereafter, we train three reward models corresponding to each kind of hallucination (middle of Figure 2).
Specifically, we first split the input of the reward model into tokens and get the index of the last token of each sub-sentence for the subsequent hallucination prediction as follows,

where ind-i is the index of the last token of the i-th sub-sentence.
n is the total number of sub-sentences and T is the tokens for the input R (response), P (prompt) and I (image).
Seach is a function that can get the index of the last token for each sub-sentence.
Finally, we can utilize the above-recognized indices to train reward models which is able to detect various kinds of hallucinations in the sub-sentence of response.
In particular, we first feed the tokens above into the reward model backbones as follows,
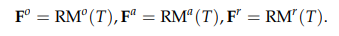
Then, we connect the output from reward models, corresponding to the last token, with an MLP classifier. Thereafter, we can predict the hallucination label with the classifier. The above process can be formulated as follows,

