https://arxiv.org/pdf/2410.02712

We introduce LLaVA-Critic, the first open-source large multimodal model (LMM) designed as a generalist evaluator to assess performance across a wide range of multimodal tasks.
LLaVA-Critic is trained using a high-quality critic instructionfollowing dataset that incorporates diverse evaluation criteria and scenarios.
Our experiments demonstrate the model’s effectiveness in two key areas:
(i) LMMas-a-Judge, where LLaVA-Critic provides reliable evaluation scores, performing on par with or surpassing GPT models on multiple evaluation benchmarks; and
(ii) Preference Learning, where it generates reward signals for preference learning, enhancing model alignment capabilities.
This work underscores the potential of open-source LMMs in self-critique and evaluation, setting the stage for future research into scalable, superhuman alignment feedback mechanisms for LMM
3 DATA COLLECTION
------------------------------------
We now introduce the data collection process for the LLaVA-Critic training dataset.
The use of GPT-4/4V as a generalist evaluator for LMMs can be broadly categorized into two settings:
(i) Pointwise scoring: GPT assigns a score to an individual candidate response, either by directly evaluating it based on predefined criteria or by scoring it relative to a fixed reference answer.
This setting can be regarded as a combination of the single-answer grading and reference grading methods discussed in Zheng et al. (2024).
(ii) Pairwise ranking: GPT compares two candidate responses to determine their relative quality (or declares a tie).
To equip LLaVA-Critic with a generalized evaluation capacity as with GPT-4V, we design a GPT-assisted pipeline to curate our training dataset for both settings. An example of LLaVA-Critic training data is shown in Table 1.
3.1 POINTWISE DATA
To train a generalist critic model for the evaluation of individual LMM responses, each pointwise training data instance consists of the following components:
a multimodal instruction (i.e., a question-image pair), a model response, an optional reference answer (depending on the evaluation prompt), an evaluation prompt, a judgment score, and the corresponding justification for the score. By organizing them in a sequence, the training sample is:

where purple parts are treated as model output to compute the auto-regressive loss, the order of Score and Reason is specified by the evaluation prompt.
We select multimodal instructions from 8 multimodal instruction tuning datasets, spanning across a wide range of tasks including:
(1) general visual conversation, detailed captioning and reasoning (LLaVA-Instruction-150k (Liu et al., 2023b), SVIT (Zhao et al., 2023));
(2) more challenging tasks such as complex reasoning (ComVint (Du et al., 2023)), text-rich understanding (LLaVAR (Zhang et al., 2023b)) and robustness-oriented instructions (LRV-Instruction (Liu et al., 2023a));
(3) various specific domains such as academic question answering (M3IT (Li et al., 2023d)), medical image understanding (LLaVA-Med (Li et al., 2023b)) and embodied decision-making (PCA-EVAL (Chen et al., 2023a)).
For each multimodal instruction, we select one or more model responses from VLFeedback (Li et al., 2023c), which collects multiple responses from 12 off-the-shelf LMMs.
Additionally, we generate responses using GPT-4o, a leading commercial LMM, to serve as high-quality reference answers.
To equip LLaVA-Critic with general evaluation capacities across various tasks, we construct an evaluation prompt pool from 7 widely used multimodal benchmarks that utilize GPT-as-a-judge, including LLaVA-in-the-Wild (Liu et al., 2023b), LLaVA-Wilder (Li et al., 2024a), Image Detailed Captioning (Li et al., 2024a), MMHal-Bench (Sun et al., 2023), MMVet (Yu et al., 2023b), WildVisionBench (Lu et al., 2024) and RefoMB (Yu et al., 2024b).
Prompts that require additional textual context( Aligning large multimodal models with factually augmented rlhfhttps://arxiv.org/abs/2309.14525 )—since they use text-only GPT-4 as the evaluator—are adjusted to focus on the input image, better aligning with the LMM evaluator setting.
To construct training data based on each evaluation prompt, we select multimodal instructions and model responses according to the specified evaluation scenario, and include reference answers from GPT-4o when necessary.
These components are then assembled into the evaluation prompt and used as input for GPT-4o (as-a-judge) to provide high-quality judgment scores and detailed justifications for model responses.
Finally, our pointwise training dataset comprises a total of 18,915 question-image pairs and 72,782 critic data samples
3.2 PAIRWISE DATA
The pairwise data consists of responses with known preference relationships.
In our training dataset, we collect the pairwise data from three open-source datasets: VLFeedback (Li et al., 2023c), RLHF (Sun et al., 2023), and RLHF-V (Yu et al., 2024a).
In the VLFeedback dataset, each (question, response) pair is rated across three different dimensions by GPT-4V.
For the same question, responses generated by different LMMs can form multiple response pairs for that question.
We randomly select 20k pairs where the average score gap between responses is greater than 0.6.
Besides, to ensure diversity in the preferences, we randomly sample 5k pairs where the two responses had identical scores across all three dimensions to serve as “Tie” training data. In the RLHF dataset, each question is annotated with preference relationships between different responses by human evaluators.
In contrast, the RLHF-V dataset consists of responses generated by LMM, which have been manually refined to produce improved responses.
From these two datasets, we collect 9.4k (RLHF) and 5.7k (RLHF-V) response pairs, each annotated with human preferences.
This results in a total of 40.1k pairwise data samples.
To enable LLaVA-Critic to provide useful detailed feedback in addition to the preference relation, we utilize GPT-4o to generate reasons behind the given preference judgment.
The training sample for pairwise data is structured in the following sequence
4 LLAVA-CRITIC
---------------------------------------
4.1 MODEL
To train the LLaVA-Critic model, we fine-tune a pre-trained LMM that already possesses strong capabilities in following diverse instructions.
This is crucial, as it ensures that the model has already been equipped to handle a wide range of vision tasks in the wild with high quality.
The evaluation ability is treated as an additional discriminative ability closely tied to these scenarios.
During training, LLaVA-Critic takes an evaluation prompt—assembling the multimodal instruction input, model response(s), and an optional reference response—as input.
It is trained to predict quantitative pointwise scores or pairwise rankings based on the criteria in the evaluation prompt, and provide detailed justifications for the assigned judgments.
Standard cross-entropy loss is applied to both judgments and justifications.
In our experiments, we start with the LLaVA-OneVision(OV) 7B/72B pretrained checkpoint and fine-tune it on the proposed LLaVA-Critic-113k dataset for 1 epoch to develop LLaVA-Critic.
We apply a learning rate of 2e-6 and a batch size of 32 for training, with other hyperparameters set to the defaults from Li et al. (2024b).
We also curate a subset with 53k samples (42k pointwise, 11k pairwise) that cover fewer instruction sources and domains. The model trained on this reduced subset is referred to as LLaVA-Critic (v0.5).
4.2 SCENARIO
==========================
1: LMM-AS-A-JUDGE
Evaluating complex tasks often requires human judges to provide feedback, which can be laborintensive.
LLaVA-Critic can serve as a general evaluator for LMM responses, reducing labor costs by automating the evaluation process.
LLaVA-Critic consistently provides reliable judgments and justifications aligned with GPT-4o or human evaluations across a range of widely used multimodal benchmarks.
This consistency holds true for both instance-level scoring and model-level ranking, as demonstrated in Sec. 5.1.
Specifically, we consider the following evaluation scenarios:
(i) Visual Chat.
--------------------------------
This task involves handling daily-life visual tasks through multimodal dialogue, requiring evaluation of task completion quality in a conversation setting.
Examples include LLaVA-Bench (Liu et al., 2023b) and LLaVAin-the-Wild (Liu et al., 2023b), which focus on simpler scenarios, while LLaVA-Wilder (Li et al., 2024a) addresses more challenging cases.
(ii) Integrated capabilities.
--------------------------------
Real-world tasks require integration of multiple basic abilities of LMMs.
MM-Vet (Yu et al., 2023b) offers a comprehensive benchmark, evaluating core vision-language capabilities including recognition, OCR, knowledge integration, language generation, spatial awareness, and math.
The Multimodal Live-Bench tests the model’s ability to generalize to new, unobserved knowledge by leveraging continuously updated news and online forums.
(iii) Preferences.
--------------------------------
This task simulates real-world multimodal interactions where models are expected to align their behavior with human preferences.
The WildVision-Bench (Lu et al., 2024) is a prime example, replicating scenarios from the online platform WildVision-Arena (WV-Arena) to evaluate preference-based interactions.
(iv) Detailed Description.
--------------------------------
This task assesses models on their ability to provide comprehensive and detailed descriptions of images and videos.
Image Detailed Captioning (Li et al., 2024a) evaluates detailed descriptions in images, while video Detailed Captioning (Zhang et al., 2024c) extends these capabilities from images to video contexts.
(v) Hallucination:
--------------------------------
This task focuses on the model’s ability to provide grounded responses based on the given context, ensuring that it avoids generating inaccurate or fabricated information, exemplified by MMHal-Bench (Sun et al., 2023).
4.3 SCENARIO 2: PREFERENCE LEARNING
==========================
Leveraging a generalist evaluator as a critic to generate reward signals for reinforcement learning is a promising research direction.
In this work, we employ LLaVA-Critic to produce AI-generated feedback datasets for diverse tasks, thereby improving the performance of supervised fine-tuned LMMs through preference alignment.
Notably, the reward signals generated by our critic can be utilized in any preference learning algorithms, including RLHF and DPO.
To quickly assess the effectiveness of the reward data, we focus on how LLaVA-Critic is incorporated into the iterative DPO training process.

Iterative Improvement.
After each round of DPO training, the updated LMM becomes the new starting checkpoint. The process is then repeated iteratively for another M − 1 rounds, using LLaVACritic to progressively improve the model’s performance based on its self-generated responses.
5.1 LMM-AS-A-JUDGE
================================
To comprehensively assess the LLaVA-Critic’s capacity in evaluating LMM responses across different scenarios, we consider two primary experimental settings:
(1) In-domain Judgments: where we measure LLaVA-Critic’s consistency with GPT-4o or human evaluators on evaluation tasks/prompts included in the LLaVA-Critic-113k training dataset; and
(2) Out-of-domain Judgments: where we apply LLaVA-Critic on evaluation tasks and prompts that are unseen during training.
For the second setting, we use the MLLM-as-a-Judge (Chen et al., 2024) benchmark to assess the alignment between LLaVA-Critic and human evaluators in generalized scenarios.
In-domain Pointwise Scoring
----------------------------------------------
To evaluate the consistency between LLaVA-Critic and GPT4o (OpenAI, 2024b) in pointwise scoring across different evaluation scenarios, as described in Sec. 4.2, we select 7 popular multimodal benchmarks and collect candidate responses from 13 commonly used LMMs alongside their GPT-4o evaluations, resulting in a total of 14174 examples (see details in Appendix B.2).
LLaVA-Critic is then tasked with providing judgments on theses samples.
We report Pearson correlation and Kendall’s Tau to measure the degree of alignment with GPT-4o in terms of instance-wise scoring and model-wise ranking respectively.
We conduct experiments based on three different baseline models: LLaVA-NeXT (LLaMA-8B) (Liu et al., 2024b; Li et al., 2024a), LLaVA-OneVision-7B, and LLaVA-OneVision-72B.
The experimental results are shown in Table 2.
Across all models and benchmarks, LLaVA-Critic variants significantly improve their corresponding baseline models in both Pearson-r and Kendall’s Tau.
(i) Data scaling.
By comparing the performance between v0.5 and full data trained LLaVA-Critic-7B, it concludes the necessity of larger size and diversity of instruction in training data.
(ii) Model scaling.
The best performance in terms of Pearson-r is achieved by LLaVA-Critic-72B with an average score of 0.754, which significantly outperforms the LLaVA-OV-72B baseline (0.634).
Similarly, in Kendall’s Tau, LLaVA-Critic-72B achieves the highest average score of 0.933, again outperforming the LLaVA-OV72B baseline (0.802).
This indicates that LLaVA-Critic-72B already possesses pointwise scoring capabilities that are quite aligned with GPT-4o.
Moreover, it is worth noting that even with a significant reduction in model parameters, LLaVA-Critic-7B still exhibits very strong point-wise scoring capabilities.
With a Pearson-r of 0.732 and a Kendall’s Tau of 0.911, its performance has not decreased significantly compared to LLaVA-Critic-72B.
This presents an advantage for deploying and utilizing LLaVA-Critic in resource-constrained environments.

Figure 2 provides a qualitative comparison between LLaVA-Critic and other LMM evaluators.
While LLaVA-OneVision often assigns fixed scores (e.g., “Tie” on WildVision-Bench or “6” on MMHalBench), LLaVA-Critic produces more diverse and balanced scores that closely align with GPT-4o, leading to consistent rankings of response models.
Notably, even without training on critic data, LLaVA-OneVision-72B demonstrates model-wise rankings that partially align with GPT-4o across four multimodal benchmarks.
In-domain Pairwise Ranking
-----------------------------------
To assess the consistency between LLaVA-Critic and human evaluators in pairwise ranking, we use the battle data from WildVision Arena (Lu et al., 2024), which comprises 11k human-annotated preference relations among LMM response pairs.
Each relation includes a question-image pair and two responses generated by different models, accompanied by a human-annotated preference (including ties).
From this dataset, we randomly sample 2k response pairs and assign them to evaluation prompts from the pairwise ranking prompt template set mentioned in Section 3.2, creating the in-domain evaluation dataset.
We report average accuracy, with and without ties, to assess alignment with human evaluators at the instance level.
For model-level consistency, we calculate the Elo rating for each response LMM and report Kendall’s Tau to measure the overall ranking correlation with human preferences.
Experimental results are reported in Table 3.
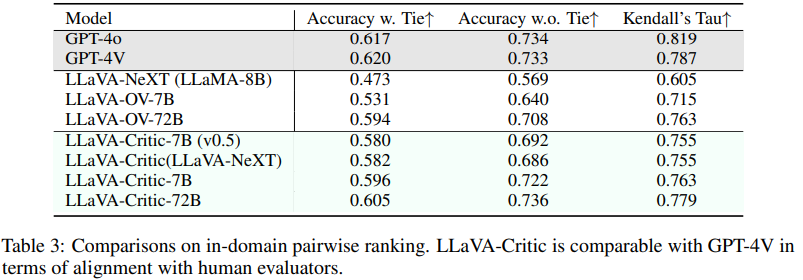
While the LLaVA models exhibit initial pairwise ranking ability, there is a notable performance gap compared to GPT-4V/4o.
After training with critic data, LLaVA-Critic achieves significant improvements.
Specifically, LLaVA-Critic-72B achieves an average accuracy of 73.6% in pairwise comparisons without tie, outperforming both GPT-4o and GPT-4V. For pairwise comparison with tie (Accuracy w. Tie) and model-wise ranking (Kendall’s Tau), LLaVA-Critic-72B shows only a marginal gap compared to GPT-4V/4o, with an accuracy of 60.5% and a score of 0.779, respectively.
Notably, despite a substantial reduction in the number of parameters, LLaVA-Critic-7B still achieves an average accuracy of 59.6% in pairwise ranking with ties and 72.2% without ties, alongside a Kendall’s tau of 0.763.
These results underscore the strong alignment between LLaVA-Critic and human evaluators in pairwise ranking LMM responses.
MLLM-as-a-Judge
==========================
MLLM-as-a-Judge (Chen et al., 2024) is a comprehensive benchmark to evaluate the degree of alignment between model-based evaluation and human evaluation.
It collects approximately 17k image-instruction-response triplets across 14 multimodal benchmarks and 6 LMM response models.
Human annotators are then employed to assess model responses under scoring, pairwise comparison and batch ranking settings, resulting in 7756, 5719, 1469 examples respectively.
In our experiments, we evaluate LLaVA-Critic in both (pointwise) scoring and pair comparison settings to assess its general alignment with human evaluators.
We report the average Pearson correlation for scoring and average accuracy for pairwise comparison, following the metrics used in the original benchmark.
We compare LLaVA-Critic with commercial models (GPT-4V/4o, Gemini-Pro (Team et al., 2023)), open-sourced LMMs, as well as Prometheus-Vision (Lee et al., 2024), which trains a LLaVA model on a curated LMM-as-a-judge dataset comprising 15k GPT-generated rubrics and 150k GPT-4V feedback data.
As shown in Table 4, LLaVA-Critic-7B surpasses all baselines except GPT-4V/4o across all settings by a considerable margin.

Built on a stronger base model, LLaVA-Critic-72B further achieves the Pearson similarity with human annotators from 0.314 to 0.393 in pointwise scoring.
For pairwise comparisons, it achieves accuracy rates of 57.8% and 71.5% with and without ties, respectively, reaching a level of alignment with human evaluators comparable to GPT-4V/4o.
We also compare different variants of LLaVA-Critic and observe performance gains with both stronger base models and larger training data, consistent with previous findings.
This again highlights the critical role of model and data scaling in building an effective and generalist open-source LMM evaluator.
More comprehensive results are provided in Appendix C.1. Qualitative Comparison.
We present example comparisons of the evaluation scores and reasons generated by LLaVA-Critic and other LMMs, with detailed examples provided in Appendix D.
The key findings are as follows: Compared to LLaVA-OneVision, LLaVA-Critic delivers more accurate judgments (Table 10), and provides more concrete, image-grounded justifications (Table 11).
The latter is crucial for reliable AI (Bai et al., 2022), as offering well-supported reasons for evaluations establishes LLaVA-Critic as a transparent evaluator of LMM responses.
5.2 PREFERENCE LEARNING
We further evaluate LLaVA-Critic’s performance in providing reward signals for iterative DPO.
LLaVA-OneVision’s supervised fine-tuned checkpoint is used as the base policy model, and questionimage pairs from LLaVA-RLHF (Sun et al., 2023) serve as the multimodal instructions.
For each pair, K = 5 candidate responses are generated through random decoding (with a temperature of 0.7 and top-p of 0.9) to ensure response diversity.
LLaVA-Critic is employed as described in Sec. 4.3 to construct the pairwise feedback data, which is then used for one epoch of DPO training.
We perform iterative DPO for M = 3 rounds in total.
To assess the effectiveness of the LLaVA-Critic’s reward signals, we evaluate the final LMM checkpoint across 6 open-ended multimodal benchmarks: four image-based tasks (LLaVA-in-the-Wild (Liu et al., 2023b), LLaVA-Wilder (Li et al., 2024a), LiveBench (Zhang et al., 2024a), and WildVisionBench (Lu et al., 2024)), one video-based task (Video Detailed Captioning (Li et al., 2024a)), and one hallucination benchmark (MMHal-Bench (Sun et al., 2023)).
We compare LLaVA-Critic with two baselines:
(1) the reward model from LLaVA-RLHF (Sun et al., 2023), which is trained on human preferences, and
(2) a naive baseline that replaces LLaVA-Critic with LLaVA-OneVision’s SFT checkpoint as a zero-shot reward model.
As shown in Table 5, preferences provided by LLaVA-Critic significantly improve LLaVAOneVision’s visual chat capacities and reduce hallucination across challenging tasks. LLaVA-Critic consistently surpasses other baseline reward models on 5 out of 6 benchmarks for the 7B base model and all 6 benchmarks for the 72B base model.
Despite the preference alignment conducted solely with images, LLaVA-Critic also enhances LLaVA-OneVision’s performance in Video Detailed Captioning (+0.12 on OV-7B and +0.26 on OV-7B), demonstrating its ability to generalize to both image and video contexts.
Additionally, we observe that Critic-7B outperforms Critic-7B-v0.5 on 5 out of 6 benchmarks, highlighting the importance of stronger reward models—trained on more diverse critic instructions—to deliver more accurate reward signals and further enhance preference learning.
Please refer to Appendix C.2 for additional results and Table 12 for a visual-chat example.
Comparison
--------------------------------------
We take LLaVA-v.1.5-7B as the base policy model, and compare LLaVA-Critic with 4 previous methods that apply preference optimization with self-generated candidate responses: LLaVARLHF (Sun et al., 2023), SIMA (Wang et al., 2024c), CSR (Zhou et al., 2024b) and RLAIF-V (Yu et al., 2024b).
These methods primarily vary in the source of reward signals: LLaVA-RLHF leverages a pretrained reward model based on human feedback; SIMA develops an in-context self-critic prompt for providing pairwise judgments; CSR incorporates sentence-level beam search with CLIP-score calibration; and RLAIF-V adopts a divide-and-conquer strategy to calculate the overall reward score by combining sentence-level judgments.
For our method, we utilize the prompts (question-image pairs) from the LLaVA-RLHF dataset and perform DPO training for 3 epoches.

As illustrated in Table 6, with only 9.4k input prompts, the reward signal provided by LLaVACritic substantially improve the base model’s performance across various open-ended visual chat benchmarks.
It achieves the best improvements of +10.1 on LLaVA-W, +3.0 on LLaVA-Wilder, +8.8 on WildVision, along with the second-highest gains of + 4.4 on LiveBench and +0.13 on MMHalBench, respectively.
At the same time, the overall capacities of LLaVA-v1.5-7B are largely preserved, as demonstrated on other comprehensive benchmarks.
This is superior to other competing methods, which either result in smaller performance gains or achieve improvements by compromising the overall capabilities on other benchmarks.
6 CONCLUSIONS
==============================
We have presented LLaVA-Critic, an open-source LMM that is trained to evaluate model performance in a wide range of multimodal scenarios.
To achieve this, we curated a high-quality critic instruction following dataset with diverse evaluation criteria.
We demonstrated the effectiveness of LLaVA-Critic in two key areas:
(1) as a generalized evaluator, LLaVA-Critic provides pointwise scores and pairwise rankings that closely align with human and GPT-4o preferences across multiple evaluation tasks, presenting a viable open-source alternative to commercial GPT models for autonomous assessment of open-ended LMM responses;
(2) in preference learning, LLaVA-Critic functions as a reliable reward model, supplying preference signals that enhance the visual chat capabilities of LMMs, surpassing the LLaVA-RLHF reward model built with human feedback.
This work represents an important step toward harnessing the self-critique capabilities of open-source LMMs, and we hope it will encourage further research into developing strong LMMs with scalable and superhuman alignment feedback.
B IMPLEMENTATION DETAILS
B.1 EVALUATION PROMPTS FOR LLAVA-CRITIC TRAINING
Pointwise prompts
-------------------------------------------------------
To construct pointwise training data, we adapt the existing evaluation prompts in 7 widely used multimodal evaluation benchmarks that employ GPT-as-a-judge.
For further details, please refer to their papers or codebases as listed below:
• LLaVA-in-the-Wild (Liu et al., 2023b): arxiv.org/abs/2304.08485
• LLaVA-Wilder (Li et al., 2024a): lmms eval/tasks/llava wilder/utils.py
• ImageDC (Li et al., 2024a): lmms eval/tasks/internal eval/dc100 en utils.py
• MMHal-Bench (Sun et al., 2023): arxiv.org/abs/2309.14525
• MM-Vet (Yu et al., 2023b): arxiv.org/abs/2308.02490
• WildVision-Arena (Lu et al., 2024): arxiv.org/abs/2406.11069
• RefoMB (Yu et al., 2024b): arxiv.org/abs/2405.17220 LLaVA-in-the-Wild, MM-Vet, MMHal-Bench and RefoMB use text-only GPT models for evaluation.
We slightly adjust their evaluation prompts to focus on visual information from the input image, rather than text-based contexts.
Pairwise prompt pool To fully develop LLaVA-Critic’s capacity of ranking LMM responses pairs across diverse scenarios, with varying format requirements and evaluation criteria, we design a set of 30 pairwise prompt templates for constructing our pairwise training data.
Due to page limits, two representative prompts are provided in Table 7.
B.2 BENCHMARK CONSTRUCTION FOR LMM-AS-A-JUDGE
In-domain pointwise scoring
---------------------------------------
To evaluate the ability of LLaVA-Critic in judging LMM-generated responses across varying performance levels, we select 13 off-the-shelf LMMs spanning across a wide range of visual chat capabilities, then collect their responses on 7 multimodal benchmarks.
The selected response models are listed below:
• GPT-4o (OpenAI, 2024b), Claude3-Sonnet (Anthropic, 2024), LLaVA-NeXT (LLaMA-8B) (Liu et al., 2024b), LLaVA-NeXT (Vicuna-7B) (Liu et al., 2024b), LLaVA-OneVision-7B (Li et al., 2024b), LLaVA-RLHF-13B (Sun et al., 2023), LLaVA-v1.5-7B (Liu et al., 2024a), LLaVA-v1.5- 13B (Liu et al., 2024a), InstructBLIP-Vicuna-7B (Dai et al., 2024), InternVL2-8B (Chen et al., 2023b), Phi-3-Vision-128k-Instruct (Abdin et al., 2024), fuyu-8B (Bavishi et al., 2023) and QwenVL-Chat (Bai et al., 2023)