https://arxiv.org/pdf/2405.14622
요약
reward 부여 방식: self-generated instruction-following score( calculated using the language decoder of the LVLM , 이거 하나로만 안되는 이유 : modality misalignment, potentially overlooking visual input information ), + the image-response relevance score, R^I (s).( We leverage CLIP-score [17] for this calculation )
3 Calibrated Self-Rewarding Vision Language Models
To address this challenge, we propose Calibrated Self-Rewarding (CSR), a novel approach aimed at improving modality alignment in LVLMs by integrating visual constraints into the self-rewarding paradigm.
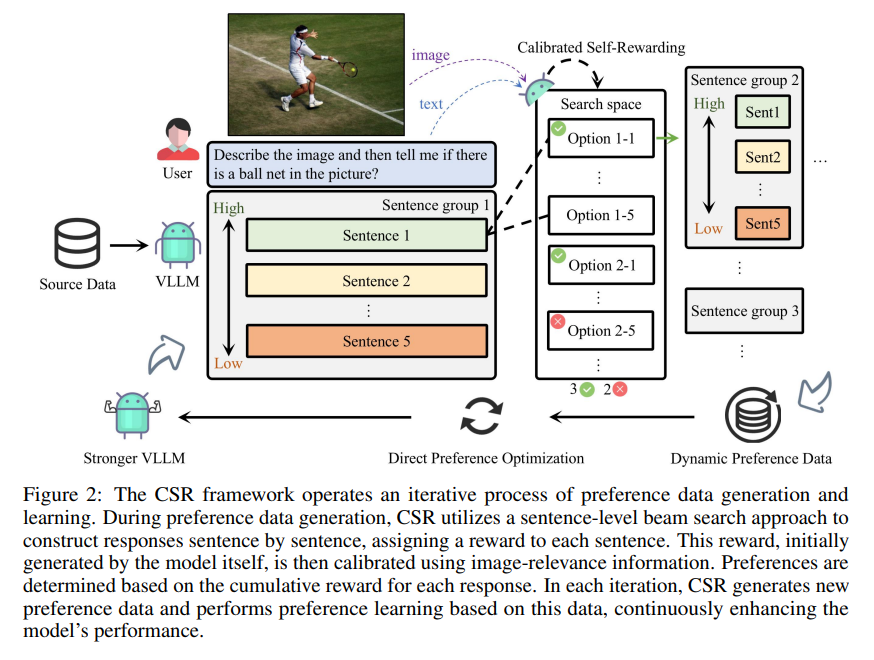
As illustrated in Figure 2, CSR trains the target LVLM by alternately performing two stages: candidate response generation and preference curation and fine-tuning. In the candidate response generation stage, we employ sentence-level beam search for each input prompt to produce fine-grained candidate responses.
During this process, the language decoder determines the initial reward for each generated sentence, which is then calibrated by incorporating an image-response relevance score.
This calibrated reward score guides the generation of subsequent sentences and finally generate the entire response.
Moving on to the preference curation and fine-tuning stage, we use the responses with the highest and lowest cumulative calibrated rewards to construct the preferred and dispreferred responses, and utilize the constructed preference pairs for fine-tuning.
In the remaining of this section, we will provide detailed explanations of CSR.
3.1 Step-Level Reward Modeling and Calibration Before delving into how to generate candidate response and construct preference data, in this section, we first discuss how to formulate the reward within CSR.
The ideal reward in the LVLM fulfills two specific criteria:
• Vision-Constrained Reward: This aspect aims to integrate image-relevance information into the reward definition of LVLMs.
By doing so, we address the limitation of LVLM in overlooking image input data when generating preferences.
3 • Step-Wise Reward: Instead of assigning a single reward for the entire response, we opt for a step-wise approach. This involves assigning rewards at each step of response generation.
Compared to a single reward, this finer-grained reward offers more detailed guidance and is more robust.
To fulfill these criteria, we propose a step-wise calibrated reward modeling strategy.
Inspired by Process-Supervised Reward Models [16], we assign a reward score, R(s), to each generated sentence s during the sentence-level beam search.
This score is a combination of two components: the self-generated instruction-following score

where No is the number of tokens in sentence s and ro represents token o in sentence s.
A higher self-generated instruction-following score indicates a stronger capability of the generated response to follow instructions.

즉, 다수의 후보 sentence들을 샘플링한뒤(이는 마침표로 구분"end of sub-sentence" marker (e.g., "." in English) as the delimiter. ) 이에 대한 reward를 equation (4)를 통해 부여 그후 top-k와 bottom-k를 선택, proceed to the subsequent round of sentence-level beam search 계속 진행 -> <EOS> 토큰에 다다를 떄까지
따라서

가 generated 되면
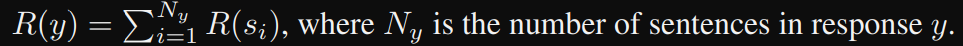
지금까지의 cumulative reward score를 계산
->
After generating candidate responses with their reward scores, our next step is to curate preference dataset. Here, for each input prompt, we select the responses with the highest and lowest cumulative calibrated reward scores as the preferred and dispreferred responses, respectively, to construct the preference dataset for fine-tuning.
각각의 iteration t 마다, preference data를

라고 정의. 이를 DPO로 finetune하면 끝
기존의 문제점
LVLMs often exhibit the hallucination phenomenon, where generated text responses appear linguistically plausible but contradict the input image, indicating a misalignment between image and text pairs. This misalignment arises because the model tends to prioritize textual information over visual input, even when both the language model and visual representations are of high quality. Existing methods leverage additional models or human annotations to curate preference data and enhance modality alignment through preference optimization. These approaches are resource-intensive and may not effectively reflect the target LVLM’s preferences, making the curated preferences easily distinguishable
따라서 ->>
Our work addresses these challenges by proposing the Calibrated Self-Rewarding (CSR) approach, which enables the model to self-improve by iteratively generating candidate responses, evaluating the reward for each response, and curating preference data for fine-tuning.

방식
sentence beam search ->
we first utilize the language decoder to establish an initial reward (i.e., sentence-level cumulative probabilities).
Subsequently, we calibrate this initial reward by incorporating an image-response relevance score, resulting in the calibrated reward score. These calibrated reward scores are utilized to guide the generation of the next batch of candidate sentences.
Finally, responses with the highest and lowest cumulative calibrated reward scores are identified as preferred and dispreferred responses, respectively, for preference fine-tuning in the subsequent iteration.
->>
we show that introducing visual constraints in the self-rewarding paradigm can improve performance
reward에 대한 2가지 기준
The ideal reward in the LVLM fulfills two specific criteria:
• Vision-Constrained Reward: This aspect aims to integrate image-relevance information into the reward definition of LVLMs. By doing so, we address the limitation of LVLM in overlooking image input data when generating preferences.
• Step-Wise Reward: Instead of assigning a single reward for the entire response, we opt for a step-wise approach. This involves assigning rewards at each step of response generation. Compared to a single reward, this finer-grained reward offers more detailed guidance and is more robust.