https://arxiv.org/pdf/2408.07199
기존의 PRM을 각 step의 correctness를 확인하게 위해 쓰인것과 달리, critic 모델을 통해 process 감독을 하고 가능한 에이젼트 action에 순위를 매김
자세히
policy(LLM actor)이 K개의 action을 제시 policy(LLM critic , 동일한 Base LLM)이 제안된 action에 순위를 매김
순위는 expansion(MCTS) 후 노드 선(MCTS)을 가이드 하는데 사용되고, DPO pair를 구성하는데 사용됨
We combine a planning and reasoning agent with MCTS inference-time search and AI self-critique for self-supervised data collection, which we then use for RL type trainin

https://arxiv.org/pdf/2408.07199

3. Preliminaries
3.1. Agent Formulation
POMDP setup (𝒪, 𝒮, 𝒜, 𝑇, 𝑅, 𝜇0, 𝛾)
observation
첫번째 O = user text instruction
"몇시 어느 레스토랑 몇명 예약해줘"
그 다음 Observation
브라우저로부터의 web page
actions
(ReAcT에 추가적인 요소가 더해짐)

따라서 joint likelihood는 다음과 같다

state
전체 observation, action의 트라젝토리를 사용할수도 있지만
inference 스피드, cost 문제, out of distribution 문제, long context등의 이유로 HTML DOM을 observation의 state에 사용하는 것은 impractical
이를 위해 histroy representation h를 사용
h(𝑡) = (a(1), . . . , a(𝑡−1), o(𝑡)). - 즉 지금까지 생성된 action, 현재 observation
https://arxiv.org/abs/2207.05608
Inner Monologue: Embodied Reasoning through Planning with Language Models
Recent works have shown how the reasoning capabilities of Large Language Models (LLMs) can be applied to domains beyond natural language processing, such as planning and interaction for robots. These embodied problems require an agent to understand many se
arxiv.org
비록 브라우저와 상호작용하기 위해 environmnet action만을 사용하지만, 에이전트의 thought and explanation actions 을 내적 독백(inner monologue)의 형태로 작동하도록 구성하여 위의 논문처럼 에이전트의 상태와 의도를 적절히 표현
이를 통해 훨씬 더 간결한 compact history representation을 사용할 수 있다. 주목할 점은 environment action 만이 브라우저 state에 영향을 미치지만, 계획, 추론 및 설명 reasoning and explanation 구성 요소는 조건화(conditioning)로 인해 이후의 결정에 영향을 미친다는 것
이러한 이유로 에이전트를 최적화할 때, 복합적인 행동(composite action)에 대한 likelihood를 계산
3.2. Fine-Tuning Language Models From Feedback
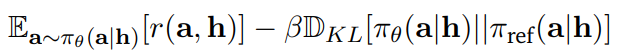
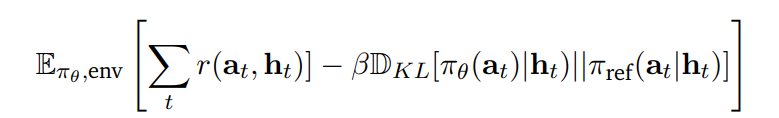
3.2.1. Reinforced Fine-Tuning
verifier 또는 reward 모델을 통해 필터링한 데이터셋으로 SFT
3.2.2. Direct Preference Optimization

PPO와 달리(online) off-policy replay buffer를 사용해 DPO의 ref모델의 comptuing 최적화
4. Preliminary Approach With Outcome Supervision
agentLite(Liu et al., 2024)https://arxiv.org/abs/2402.15538 연구에서 지정한 동일한 에이전트 구성을 통합하여, 우리 미세 조정 모델과 xLAMhttps://arxiv.org/abs/2402.15506 기본 모델의 성능을 비교
5. Agent Search
5.1.1. Action Selection With AI Process Supervision
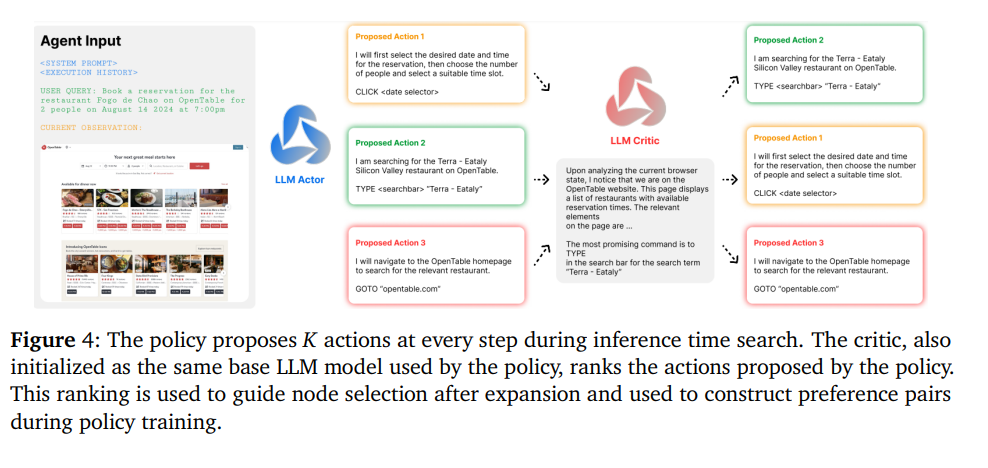
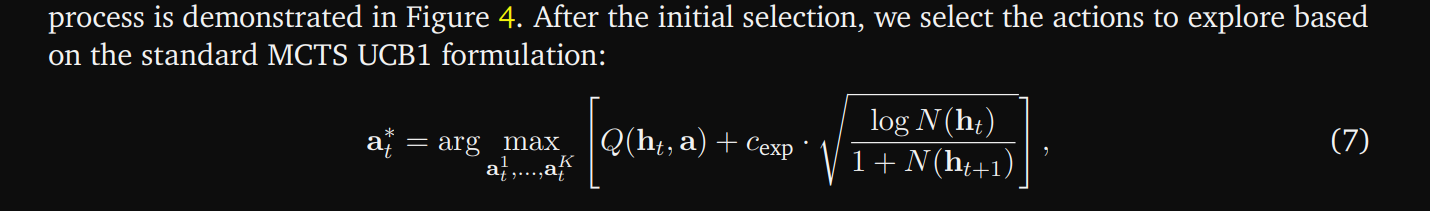
5.1.2. Expansion and Backtracking
The environment returns a reward at the end of the trajectory, 𝑅, where 𝑅 = 1 if the agent was successful and 𝑅 = 0 otherwise
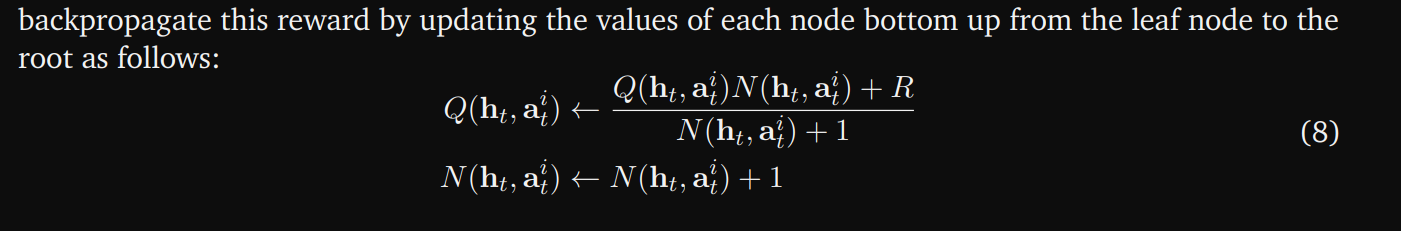

5.2. Improving Zero-Shot Performance with Reinforcement Learning

