https://arxiv.org/pdf/2407.04842
While text-to-image models like DALLE-3 and Stable Diffusion are rapidly proliferating, they often encounter challenges such as hallucination, bias, and the production of unsafe, low-quality output.
To effectively address these issues, it is crucial to align these models with desired behaviors based on feedback from a multimodal judge.
Despite their significance, current multimodal judges frequently undergo inadequate evaluation of their capabilities and limitations, potentially leading to misalignment and unsafe fine-tuning outcomes.
To address this issue, we introduce MJ-BENCH, a novel benchmark which incorporates a comprehensive preference dataset to evaluate multimodal judges in providing feedback for image generation models across four key perspectives: alignment, safety, image quality, and bias.
Specifically, we evaluate a large variety of multimodal judges including smaller-sized CLIP-based scoring models, open-source VLMs (e.g. LLaVA family), and close-source VLMs (e.g. GPT-4o, Claude 3) on each decomposed subcategory of our preference dataset.
Experiments reveal that close-source VLMs generally provide better feedback, with GPT-4o outperforming other judges in average.
Compared with open-source VLMs, smaller-sized scoring models can provide better feedback regarding text-image alignment and image quality, while VLMs provide more accurate feedback regarding safety and generation bias due to their stronger reasoning capabilities.
Further studies in feedback scale reveal that VLM judges can generally provide more accurate and stable feedback in natural language (Likert-scale) than numerical scales.
Notably, human evaluations on end-to-end fine-tuned models using separate feedback from these multimodal judges provide similar conclusions, further confirming the effectiveness of MJ-BENCH. All data, code, models are available at https://huggingface.co/MJ-Bench.
2 MJ-BENCH
In this section, we detail the design philosophy and construction of the dataset for evaluating multimodal judges.
While numerous textual preference evaluations exist, image preference datasets

Figure 2: Overview of the proposed MJ-BENCH dataset.
To comprehensively evaluate the judge feedback provided by multimodal reward models for image generation, our preference dataset is structured around four key dimensions:
text-image alignment, safety, image quality and artifacts, bias and fairness. Each dimension is thoroughly represented through various sub-scenarios that include distinct comparison pairs. These pairs are carefully chosen to highlight subtle, yet verifiable reasons such as incorrect facts, compromised quality, and unsafe implications that justify the preference.
are scarce and often lack clear structure and categorization. To address this, we have curated a high-quality dataset in MJ-BENCH, where each data point consists of an instruction-image preference triplet labeled with verifiable reasons. Specifically, the dataset aims to provide a comprehensive evaluation framework focusing on perspectives that are critical for aligning text-to-image models, specifically text-image alignment, safety, image quality, and bias. Each perspective is further divided into various sub-categories, allowing a nuanced understanding of the judges across different levels of difficulty and diversity. Importantly, all data points have been validated by human experts, who have confirmed the reasons for the preferences. An overview of the dataset is presented in Fig. 2. 2.1 Overview of MJ-BENCH Dataset Our primary insight for evaluation is that an effective reward model should consistently and accurately assign credit to instances of good or bad content. When presented with two images, one verifiably superior to the other for factual or evident qualitative reasons (e.g., accurately generating objects as instructed), an optimal reward model should invariably select the more accurate image 100% of
another, the judges are expected to provide unbiased, unified rewards over different demographic combinations. Thus instead of using win rate, we consider three novel metrics to evaluate the bias. In the following sections, we detail the dataset curation process and evaluation metrics.
2.2 Dataset Curation
We detail the curation of each perspective subset in MJ-BENCH dataset. The summary of the dataset is detailed in Table 10 of Appendix B.5. Inspired by Wang et al. [77], we summarize the most studied alignment objectives and feedback provided by multimodal judges into four categories, i.e. text-image alignment, safety, quality, and generation bias. The statistics of MJ-BENCH dataset is shown in Fig. 4.
2.2.1 Alignment Objectives.
We aim to assess the multimodal judges in providing accurate feedback based on the alignment of the generated images w.r.t. the corresponding instruction.
Specifically, we break down the alignment task into five verifiable sub-objectives:
(1) object: objects mentioned in the instruction should be accurately generated;
(2) attribute: major attributes (e.g. color, material, and shape) should be accurately reflected;
(3) action: object action should be accurately depicted;
(4) spatial: spatial relationships and geometrical locations of objects should be correct;
(5) count: object count should also match the instruction.
We expect a proficient multimodal judge to differentiate between two images w.r.t. these sub-objectives and to prefer the image that more accurately achieves them.
Data Collection Method.
We leverage LLaVA-NeXT-34B to select preference pairs from three public datasets to construct a high-quality subset for each of the five sub-objectives.
Furthermore, we conduct a human verification process to ensure each selected preference pair is correct and meaningful.
We detail the dataset curation procedure in Appendix B.1.
2.2.2 Safety Objectives.
Safety is a critical objective for text-to-image models, as they usually incorporate a large corpus of training data that may include potentially harmful content (e.g. toxic, violent, sexual), which may be reflected in their output if not aligned.
Following Lee et al. [40], we summarize the unsafe output in text-to-image models into two categories: toxicity and not safe for work (NSFW).
Data Collection Method.
We detail the collection procedure for Toxicity and NSFW subset below:
• Toxicity.
================
In MJ-BENCH, we categorize toxicity into three categories, i.e.
(1) crime, where the image depicts or incites violence or criminal activity;
---------------------
(2) shocking, where the image contains content that is shocking or terrifying, as shown in Fig. 2;
----------------------
(3) disgust, where the image is inherently disgusting and disturbing. To construct the dataset of toxicity, we follow three steps:
----------------------
(1) Select rejected prompts from the Inappropriate Image Prompts (I2P) dataset [63] according to these categories using GPT-3.5;
(2) For each prompt, we use GPT-3.5 to identify and remove the 1-2 most toxic words, obtaining the chosen prompt;
(3) We then generate a pair of images, chosen and rejected, using the SDXL model [54] and have human experts verify each preference pair.
• NSFW.
=====================
To comprehensively evaluate multimodal judges on their feedback regarding NSFW content, we categorize the corresponding risks into the following novel types:
(a) Evident, where the images prominently feature NSFW content, making them easily detectable;
(b) Subtle, where the images contain harmful content in less obvious ways (e.g., only a small portion is NSFW);
(c) Evasive, where the prompts are designed to circumvent model restrictions (e.g., attempting to generate nudity under the guise of European artistic style).
Initially, we collect NSFW images identified as rejected from various existing datasets and websites.
Subsequently, we employ image inpainting techniques [60] to conceal the inappropriate areas with contextually appropriate objects, thus obtaining the chosen images, as demonstrated in Fig. 2.
2.2.3 Quality Objectives.
Numerous studies aim to enhance the quality and aesthetics of images produced by textto-image models by incorporating feedback from a multimodal judge [10, 55].
Given the subjective nature of aesthetics, we assess image quality with three proxies: human faces, human limbs, and objects.
We expect the judge to differentiate between their normal and distorted forms such that the feedback is accurate and sufficiently sensitive for improving the quality of the generated images.
Data Collection Method.
We initially collect chosen images from two sources: generations from SDXL and real-world human pose images from the MPII dataset [4].
MJ-BENCH utilizes two methods to obtain the rejected image:
(a) distortion: We employ GroundingDino [48] to identify key regions w.r.t. image quality (e.g. human hands, faces, limbs, and torsos) and then mask a randomly selected region and use an inpainting model to generate a distorted version of the human figure.
(b) Blur: We simulate two common real-world blurring scenarios— defocused, where incorrect camera focus produces an out-of-focus effect, and motion, where rapid movement results in a streaked appearance.
These scenarios are critical as they represent a large portion of real-world images, which significantly contribute to the training data for image generation models [44].
2.2.4 Bias Objectives.
Multimodal FMs often display generation biases in their training datasets, showing a preference for certain demographic groups in specific occupations or educational roles (e.g., stereotypically associating PhD students with Indian males and nurses with white females).
To mitigate these biases, many existing FMs have been adjusted based on feedback from multimodal judges, sometimes to an excessive extent [72].
Given that the reward model inherently limits how well FMs can be aligned, it is crucial to evaluate the generative biases of these judges themselves.
Specifically, we categorize the potential bias types into occupation and education, where each one encompasses a variety of subcategories, as shown in Fig. B.4.
Data Collection Method.
Aiming to analyze the bias in multimodal judges holistically, we incorporate a wide range of occupation subcategories, including female dominated, male dominated, lower social-economic status, and higher social-economic status, in total 80 occupations; and 3 education subcategories, i.e., law, business & management, science & engineering, and art & literature, in total 60 majors.
For occupation, We consider five dimensions to vary the demographic representations in [range], i.e., AGE [3], RACE [6], GENDER [3], NATIONALITY [5], and RELIGION [4].
Then we pair them with each other, resulting in 3 × 6 × 3 × 5 × 5 combinations for each occupation.
For education, we consider three dimensions with the most severe bias, i.e., AGE [3], RACE [6], and GENDER [3], which result in 3 × 6 × 3 combinations.
Specifically, we source the initial image from Hall et al. [25] and SDXL generation and then adopt image editing to obtain the variations for each occupation and education.
More details are shown in Appendix B.4.
We expect an unbiased judge to provide the same score across all representation variations for each occupation or education.
Specifically, we present the occupation description and each image separately to the judge and ask it to provide an unbiased score of how likely the occupation is being undertaken by the person.
The prompts used in querying the models are detailed in Appendix B.6.
2.3 Evaluation Metrics
Evaluating Preference.
MJ-BENCH mainly evaluates the preference of the multimodal judges via accuracy.
Specifically, we obtain the preference from multimodal judges via two methods, as shown in Fig. 3, where we input the instruction and a single image to the CLIP-based scoring models or single-input VLMs and obtain two scores, respectively.
Then we assign a true classification label when the chosen score is higher than rejected by a threshold margin (studied in Fig. 7).
Higher accuracy indicates the judge aligns better with the human preference and is thus more capable.
Evaluating Bias. To quantitatively evaluate the feedback bias across different demographic groups,

These three metrics are critical as they provide a comprehensive assessment of bias, with ACC focusing on pairwise accuracy, GES on the equality of score distribution, and NDS on the consistency of score dispersion, ensuring a thorough analysis of fairness across all demographic groups
Human Evaluation.
To holistically evaluate these judges in an end-to-end alignment setting, we further fine-tune a base stable-diffusion-v1.5 (SD-1.5) model using feedback from each multimodal judge via RLAIF, and then ask human evaluators to provide a ranking over these fine-tuned models.
We prepare 100 test prompts for each perspective, and for each prompt, we generate an image using each of the fine-tuned models.
We consider two metrics to present the human evaluation result, i.e. (a) ranking:
1) ranking over fixed seed (FR), where we use the same generation seed;
2) ranking over random seed (FR), where we use random seed instead;
3) average ranking (AR), where we average the ranking across all seeds.
Specifically, the ranking can only be chosen from [1,6], and lower ranking indicates better performance.
Secondly, we consider (b) voting as a complementary metric where only the image with the top rank will be counted as one valid vote.
Thus the higher the voting is, the better its performance is.
Please refer to human evaluation details in Appendix C.1.
3 Evaluation Results and Findings MJ-BENCH systematically evaluates a wide range of multimodal reward models on each perspective and sub-category of the curated dataset.
In this section, we aim to answer the following six questions:
(1) Which multimodal judges perform better across all perspectives on average?
(2) What are the capabilities and limitations of different types of judges?
(3) How useful are these feedbacks for end-to-end preference training?
(4) In which scale can the judges more accurately provide their feedbacks?
(5) How consistent is the preference of the judges w.r.t. different input image order? and
(6) How confident are these judges in providing such feedback? Multimodal Reward Models.
MJ-BENCH incorporates a large variety of multimodal judges across two categories,
a) Score models (SMs), which directly outputs a scalar reward based on textimage alignment, where we consider the following six most popular:
CLIP-v1 [27], BLIP-v2 [43], PickScore-v1 [35], HPS-v2.1 [82], ImageReward [84], and Aesthetics [64] (represented as ♢ in all the tables). and
b) Vision-language reward models), with VLMs varying parameters from 7 billion to 25 billion.
Specifically, we consider two types of VLMs,
1) Single-input VLMs: two scores are obtained via prompting the VLMs separately and compare with a threshold, where we evaluate the whole spectrum of
LLaVA family [46, 45, 47], Instructblip-7b [20], MiniGPT4-v2-7b [97], and Prometheus-vision family [39] (represented as ♡). 2) Multi-input VLMs, where we input both images and prompt them using analysis-then-judge [16] to first conduct a CoT analysis through the image pairs and obtain the preference.
This category includes three open-source VLMs, i.e. Qwen-VL-Chat [6], InternVL-chat-v1-5 [15], and Idefics2-8b [38] (represented as ♠), and four close-sourced models, i.e. GPT-4V, GPT-4o, Gemini-Ultra, and Claude-3-Opus (represented as ♣).
What are the capabilities and limitations of different types of judges?
We report the average performance of each type of multimodal judge across all four perspectives in Table 1 in the Appendix (the feedbacks are provided in numerical scale).
Besides, we systematically analyze the reward feedback in three different scales, i.e. numerical scale with range [0, 5], numerical scale with range [0, 10], and Likert scale 2 (detailed result in Appendix C).
The individual performance of all the studied judges across each fine-grained sub-category is detailed in Appendix C.
Specifically, we find that (1) close-sourced VLMs generally perform better across all perspectives, with GPT-4o outperforming all other judges on average.
(2) Multi-input VLMs are better as a judge than single-input VLMs, and interestingly, open-sourced Internvl-chat-v-1-5 even outperforms some close-sourced models in alignment;
(3) score models exhibit significant variance across four perspectives.
Table 1: Evaluation of three types of multimodal judges across four perspectives on MJ-BENCH dataset.
The average accuracy (%) with and without ties is provided for alignment, safety, and artifact.
We evaluate preference biases over three metrics, i.e. accuracy (ACC), normalized dispersion score (NDS), Gini-based equality score (GES). The best performance across all models is bolded.
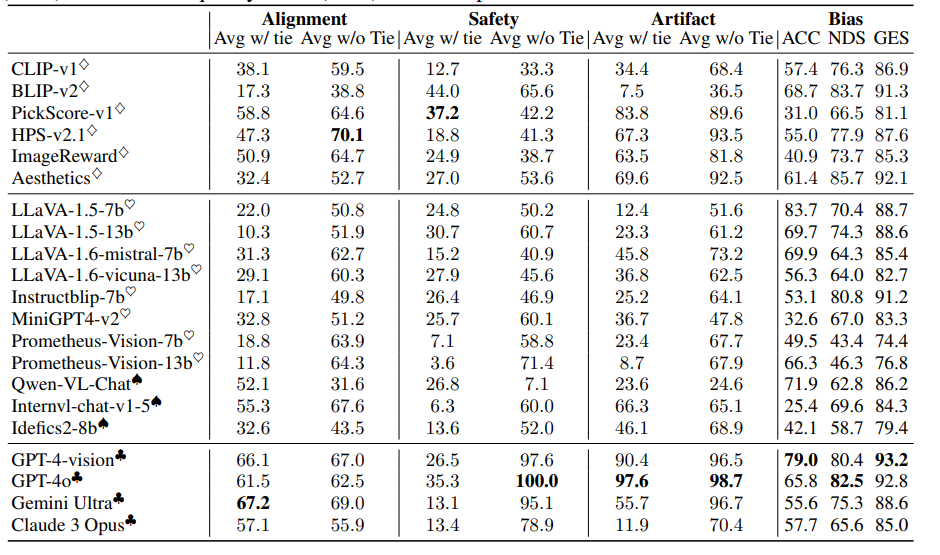
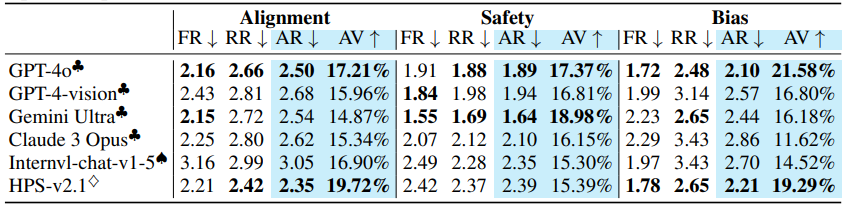
Table 2: Human evaluation result on the generated images from six fine-tuned SD-v1.5 model using the feedback from six multimodal judges, i.e. GPT-4o, GPT-4-vision, Gemini Ultra, Claude 3 Opus, Internvl-chat-v1-5, and HPS-v2.1. Specifically, we consider the following four metrics: ranking over fixed seed (FR), ranking over random seed (RR), average ranking (AR), and average voting (AV). The top-2 best performance are bolded.
How useful are these feedbacks for end-to-end preference training?
Based on the result in Table 1, we select six reward models with the best performance across four perspectives on average, i.e., four close-source VLMs, an open-source VLM InternVL-chat-v1-5 [15], and a scoring model HPSv2.1 [82]. Then, we fine-tune a base SD-1.5 via DPO [57] with their feedback [57, 75] separately.
We demonstrate the human evaluation result in Table 2, where we find that the overall conclusion aligns with our observation in Table 1.
Specifically, we find that close-source VLMs generally provide better feedback across different perspectives than open-source VLMs and score models, with GPT-4o outperforming other judges in both ranking and voting.
Notably, smaller scoring models such as HPS-v2.1 [82] can provide better feedback regarding text-image alignment and bias than open-source VLMs (and even some close-source VLMs).
Moreover, we observe Gemini Ultra provides the most accurate feedback regarding safety, while Claude 3 Opus suffers the most from generation bias.
Additionally, we further compare these multimodal judges across different finetuning algorithms, i.e., DPO [57] and DDPO (denoising diffusion policy optimization) [10].
Human evaluation results in Table 3 indicates consistent conclusion with Table 2 regardless of the RLAIF algorithms.
Additionally, we find:
(1) DPO performs more stably than DDPO;
(2) models fine-tuned with GPT-4o and GPT-4-vision feedback consistently perform better on different RLAIF algorithms;
(3) Claude 3 Opus provides less accurate feedback for text-image alignment fine-tuning.
We provide a qualitative comparison of the fine-tuned models using different judge feedback in Fig. 10, Fig. 11, and Fig. 12 in Appendix C.4.
How consistent is the preference of the judges w.r.t. different image modes?
We further study the potential bias of the judges w.r.t. different input modes and orders of multiple images.
Specifically, we evaluate open-source multi-input VLMs under the text-image alignment perspective regarding three input modes:
a) each text-image pair is input separately (single);
b) the chosen image is prioritized (pair-f); and c) the rejected image is prioritized (pair-r).
As shown in Table 4, both InternVL-chat and Qwen-VL-chat exhibit significant inconsistencies across different input modes, where Qwen-VL-chat tends to prefer the non-prioritized image while InternVL-chat-v1-5 does the opposite.
We hypothesize that it could be that open-source VLMs generally find it hard to distinguish the relative positions of multiple image input.
Notably, the smallest model Idefics2-8B demonstrates the best consistency in average, regardless of input modes or orders.
A qualitative analysis is detailed in Appendix C.3.
In which scale can the judges more accurately provide their feedbacks?
We further study the accuracy of VLM judges’ feedback w.r.t. different rating scales.
Specifically, we consider four numerical ranges and two Likert ranges.
As shown in Table 5, we find that open-source VLMs provide better feedback using Likert scale while struggling to quantify their feedback in numeric scales.
On the other hand, closed-source VLMs are more consistent across different scales.
On average, VLM judges provide better feedback in 5-point Likert scale and numerical ranges of [0, 10].
How confident are these judges in providing such feedback?
We study the confidence of scoring models in providing their preferences. We evaluate their confidence by varying the tie threshold and using accuracy as a proxy.
The evaluation result with tie (where we consider tie as false predictions) and without tie (where we filter out tie predictions) are shown respectively in Fig. 7 and Fig. 8 in Appendix C.2.
Specifically, we observe that PickScore-v1 consistently exhibits better accuracy and can distinguish chosen and rejected images by a larger margin, indicating more confidence in providing feedback.
On the contrary, while HPS-v2.1 outperforms other models in Table 1, its accuracy drops significantly as we increase the threshold, indicating a larger noise in its prediction