https://arxiv.org/abs/2405.17220
Learning from feedback reduces the hallucination of multimodal large language models (MLLMs) by aligning them with human preferences.
While traditional methods rely on labor-intensive and time-consuming manual labeling, recent approaches employing models as automatic labelers have shown promising results without human intervention.
However, these methods heavily rely on costly proprietary models like GPT-4V, resulting in scalability issues.
Moreover, this paradigm essentially distills the proprietary models to provide a temporary solution to quickly bridge the performance gap.
As this gap continues to shrink, the community is soon facing the essential challenge of aligning MLLMs using labeler models of comparable capability.
In this work, we introduce RLAIF-V, a novel framework that aligns MLLMs in a fully open-source paradigm for super GPT-4V trustworthiness.
RLAIF-V maximally exploits the open-source feedback from two perspectives, including high-quality feedback data and online feedback learning algorithm.
In order to better expose the difference in trustworthiness, we propose a novel deconfounded candidate response generation strategy.
To enhance the accuracy of pairwise feedback data from open-source MLLMs, we employ a divide-and-conquer approach that breaks down the response into atomic claims, simplifying the task to obtain more reliable results.
For the feedback learning algorithm, RLAIF-V mitigates the distribution shift problem of vanilla direct preference optimization in an online learning fashion, improving both the learning performance and efficiency.
Extensive experiments on seven benchmarks in both automatic and human evaluation show that RLAIF-V substantially enhances the trustworthiness of models without sacrificing performance on other tasks.
Using a 34B model as labeler, RLAIF-V 7B model reduces object hallucination by 82.9% and overall hallucination by 42.1%, outperforming the labeler model.
Remarkably, RLAIF-V also reveals the selfalignment potential of open-source MLLMs, where a 12B model can learn from the feedback of itself to achieve less than 29.5% overall hallucination rate, surpassing GPT-4V (45.9%) by a large margin.
The results shed light on a promising route to enhance the efficacy of leading-edge MLLMs
2 RLAIF-V
In this section, we first elaborate on how to collect high-quality AI feedback from open-source MLLMs by introducing the response collection and evaluation process.
Then we introduce the iterative alignment approach to mitigate the distribution shift problem and thus improve the scalability.
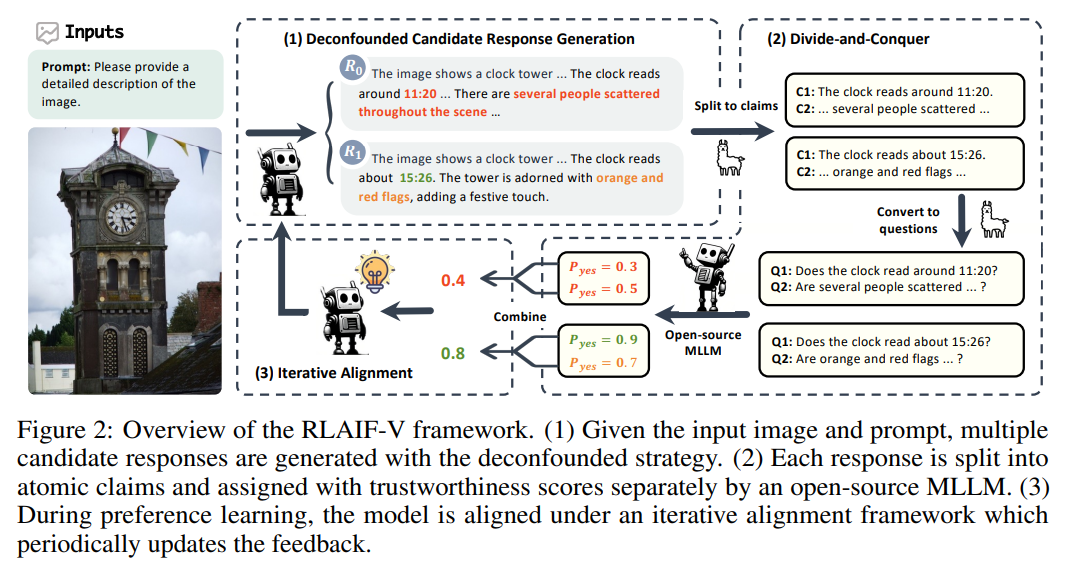
See Figure 2 for an overview of the RLAIF-V framework.
2.1 Response Generation
The feedback collected for preference learning is in the form of comparison pairs, where each pair includes a preferred response yw and an inferior response yl to the same input x (including the image and prompt).
During training, the model learns preferences by distinguishing the differences between yw and yl .
However, these differences can be complex and consist of many factors including not only the meaning of content but also textual styles such as the use of specific words or structure of the text, making the learning more difficult.
To expose the genuine differences in trustworthiness between responses, we propose a novel deconfounded strategy to generate candidate responses.
Specifically, we ask the model to generate n candidate responses {y1, y2, · · · , yn} through sampling decoding with different random seeds, where input x and decoding parameters are invariant.
In this way, yw and yl are sampled from the same distribution and consequently share similar textual styles and linguistic patterns.
During training, the model can effectively concentrate on the differences in trustworthiness.
In our experiments, we find the deconfounded strategy can significantly improve the learning efficiency (see Section 3.3).
2.2 Response Evaluation
Evaluating the quality of model responses is a challenging task even for human annotators due to the complexity of full responses.
Existing methods using models as labelers rely on costly API of proprietary models with extraordinary instruction-following and task-solving capabilities [61], resulting in scalability issues.
In contrast, we employ a divide-and-conquer approach to simplify the task to achieve more reliable results from open-source MLLMs.
The detail of collecting high-quality feedback with this approach is described as follows:
Divide.
------------
The complexity of full responses makes the holistic assessment of response quality hard to acquire based on existing open-source MLLMs [6].
One of the important complexity causes is that a full response might contain multiple statements and specific textual structure which interferes with the recognition of incorrect spans.
To make such a complicated task solvable, we decompose the response evaluation into atomic claim evaluation, as shown in Figure 2.
Specifically, we prompt a large language model to split a response y into atomic claims {c1, c2, · · · , cm}, which can be evaluated separately, by extracting facts excluding opinions and subjective statements.
Conquer.
------------
To access the trustworthiness quality of a claim c (e.g., “The clock reads around 11:20.”), we first convert it into a polar question like “Does the clock read around 11:20?”, which can be answered with simply yes or no, without introducing any extra content.
For each atomic polar question, we ask an open-source MLLM to generate the confidence of agreement and disagreement as the claim score sc = (pyes, pno), where pyes is the probability of answering with “Yes” or “yes” and pno is the probability of answering with “No” or “no”.
A higher pyes score suggests the corresponding claim is considered more trustworthy by the labeler model.
The scores collected in this way are generally more accurate compared with directly querying the evaluation result of the full response since the claims are simpler in both structure and content.
Combine.
-----------------------
After obtaining the quality assessment of each claim, we finally combine them into the score of the whole response.
For each response, we denote the number of claims having pno > pyes as nrej , measuring how many incorrect claims are recognized by the labeler model.
We use −n^rej as the final score S of the response, where a higher score indicates less incorrectness of the content.
Given the score of each response, we can now construct a preference dataset for training.
For each instruction x, we keep all response pairs (y, y′ ) such that S > S′ and choose the higher score response y as the preferred response.
To save the training cost, we randomly sample at most 2 pairs for each instruction and we find such filtering process only causes minor performance drop.
We also investigate the effectiveness of more combining methods (see Appendix C.1).

2.3 Iterative Alignment DPO is widely used to align MLLMs with human preference.
However, naive DPO faces the distribution shift problem, i.e., the preference data is static during training process while model output distribution is constantly shifting [14].
As a result, the data distribution might deviate from the expected feedback distribution and cause sub-optimal alignment results.
Mitigating the distribution shift problem requires updating the feedback data constantly during the training process.
However, collecting new feedback data at each optimization step is costly and makes the training unstable.
We tackle this problem by conducting the alignment process including both data collection and training in an iterative manner.
The iterative alignment is presented in Algorithm 1.
Specifically, we select N multimodal instructions at the beginning of each iteration and leverage the deconfounded strategy to generate n candidate responses for each instruction with the latest
